DeFi Protocol Types Part 2: Yield, Bridges & Governance
Series: Web3 Security Zero se Advance 🛡️ | Article #18
By HackerMD | 30 min read
Continue reading on Medium »
 看GitHub源码或英文文档时,还在用谷歌翻译来回切换?翻译不准、网络抽风、代码被转义?本文分享一款开源、可本地部署的翻译工具LibreTranslate,从安装、使用到与ArgosTranslate的对比选择,帮你搭建流畅阅读外文技术资料的翻译神器。
( 1
min )
看GitHub源码或英文文档时,还在用谷歌翻译来回切换?翻译不准、网络抽风、代码被转义?本文分享一款开源、可本地部署的翻译工具LibreTranslate,从安装、使用到与ArgosTranslate的对比选择,帮你搭建流畅阅读外文技术资料的翻译神器。
( 1
min )
 前言 想做一个炫酷的 3D 中国地图,但觉得 Three.js 太难?WebGL 太复杂?GeoJSON 是什么鬼? 这篇文章教你用 AI 写提示词,零基础也能快速生成一个可交互的 3D 区划地图。不需要手写一行代码,只需要说人话。 最终效果:可拖拽旋转、缩放、鼠标悬停高亮的 3D 中国省份地图。
( 3
min )
前言 想做一个炫酷的 3D 中国地图,但觉得 Three.js 太难?WebGL 太复杂?GeoJSON 是什么鬼? 这篇文章教你用 AI 写提示词,零基础也能快速生成一个可交互的 3D 区划地图。不需要手写一行代码,只需要说人话。 最终效果:可拖拽旋转、缩放、鼠标悬停高亮的 3D 中国省份地图。
( 3
min )
 上个月我们做了一个实验:把一个 180K 行的 Spring Boot 单体代码库接入 Claude Code,让它做一次全量架构分析。 结果 Claude 给出了一份比我们技术 lead 更细的依赖关系图,还发现了三处我们自己没注意到的循环依赖。 听起来很美好。但在那之前,我们踩了整整 6 周的坑
( 4
min )
代码可以构建世界,但生活中的乐趣远不止于此。这里是我一周的精选。 周刊开源(Github:wmyskxz/weekly),欢迎提交 issue,投稿或推荐精彩内容。 题图 2026 年 2 月,一支由 16 名非洲和国际专家组成的科考队进入安哥拉东部偏远的 Lisima 高原,发现数十个科学界从未记
( 4
min )
一、先看一个模式匹配的Case 该Case是一个使用模式匹配检测回文算法,只有一行代码 这是不是你见过最简洁的检测回文代码 但是这里面用到了不少模式匹配 有逻辑模式、列表模式、var模式和切片模式 模式匹配不仅仅是语法糖,在.net中有很高的地位 所以SourceGenerator非常有必要支持生成
( 4
min )
上个月我们做了一个实验:把一个 180K 行的 Spring Boot 单体代码库接入 Claude Code,让它做一次全量架构分析。 结果 Claude 给出了一份比我们技术 lead 更细的依赖关系图,还发现了三处我们自己没注意到的循环依赖。 听起来很美好。但在那之前,我们踩了整整 6 周的坑
( 4
min )
代码可以构建世界,但生活中的乐趣远不止于此。这里是我一周的精选。 周刊开源(Github:wmyskxz/weekly),欢迎提交 issue,投稿或推荐精彩内容。 题图 2026 年 2 月,一支由 16 名非洲和国际专家组成的科考队进入安哥拉东部偏远的 Lisima 高原,发现数十个科学界从未记
( 4
min )
一、先看一个模式匹配的Case 该Case是一个使用模式匹配检测回文算法,只有一行代码 这是不是你见过最简洁的检测回文代码 但是这里面用到了不少模式匹配 有逻辑模式、列表模式、var模式和切片模式 模式匹配不仅仅是语法糖,在.net中有很高的地位 所以SourceGenerator非常有必要支持生成
( 4
min )
 上一篇:《一个目录一个 Agent,Vercel Eve 的这套 Agent 架构设计太舒服了!》 我们聊了 Eve 为什么值得关注:它不是再提供一种模型调用写法,而是把 Agent 运行所需的项目结构、持久执行、沙箱、审批、渠道和评测等能力,放进一套 filesystem-first 的工程框架里
( 3
min )
上一篇:《一个目录一个 Agent,Vercel Eve 的这套 Agent 架构设计太舒服了!》 我们聊了 Eve 为什么值得关注:它不是再提供一种模型调用写法,而是把 Agent 运行所需的项目结构、持久执行、沙箱、审批、渠道和评测等能力,放进一套 filesystem-first 的工程框架里
( 3
min )
 本文深度剖析纯前端 JSON 工具的完整实现。基于 Web Worker 彻底解决大文件解析卡顿;自研智能语法修复引擎;并分享 esbuild 独立构建 Worker + manifest 映射的工程化最佳实践,附完整性能基准测试数据。
( 11
min )
本文深度剖析纯前端 JSON 工具的完整实现。基于 Web Worker 彻底解决大文件解析卡顿;自研智能语法修复引擎;并分享 esbuild 独立构建 Worker + manifest 映射的工程化最佳实践,附完整性能基准测试数据。
( 11
min )
 大家好,我是小富~ 这期给大家分享一个我开发的工具! 最近做了一个开发者专属的 JSON 工具 easy-json!在线体验地址:easyjson.xiaofucode.com,不管是什么奇形怪状的 JSON 字符串,扔进去都能智能解析,先看效果是不是还挺能打的 现在网上这类工具确实不少,我也用过很
( 2
min )
大家好,我是小富~ 这期给大家分享一个我开发的工具! 最近做了一个开发者专属的 JSON 工具 easy-json!在线体验地址:easyjson.xiaofucode.com,不管是什么奇形怪状的 JSON 字符串,扔进去都能智能解析,先看效果是不是还挺能打的 现在网上这类工具确实不少,我也用过很
( 2
min )
 `ChatHistoryMemoryProvider`利用我们提供的向量数据库,对每次调用产生的消息针对指定的Scope维度进行存储,并将当前消息作为查询文本,结合设定的Scope维度检索历史消息作为上下文的一部分来参与LLM的推理。除了这种需要我们们自己搭建和维护的基于向量数据库的解决方案之外,我...
( 3
min )
`ChatHistoryMemoryProvider`利用我们提供的向量数据库,对每次调用产生的消息针对指定的Scope维度进行存储,并将当前消息作为查询文本,结合设定的Scope维度检索历史消息作为上下文的一部分来参与LLM的推理。除了这种需要我们们自己搭建和维护的基于向量数据库的解决方案之外,我...
( 3
min )
 强化学习通过人工打分排序调整模型行为,塑造出不同大模型性格。Claude变得保守严谨,遇到不确定问题倾向于说不清楚。ChatGPT变得健谈,愿意尝试回答各种问题。对齐人类偏好是第三阶段训练的核心,直接决定模型好不好用。
( 1
min )
强化学习通过人工打分排序调整模型行为,塑造出不同大模型性格。Claude变得保守严谨,遇到不确定问题倾向于说不清楚。ChatGPT变得健谈,愿意尝试回答各种问题。对齐人类偏好是第三阶段训练的核心,直接决定模型好不好用。
( 1
min )
 拆解 Coding Agent 从 Prompt 到 Loop 的系统化改造:触发、隔离、验证、状态和人工闸门。 原文链接:AI 小老六 导语 过去一段时间,很多人使用 Coding Agent 的方式其实还停留在"远程结对":把需求写清楚,补一段上下文,等它返回结果,再继续追问。这个办法有用,但杠
( 2
min )
Fable 5 被关停前 72 小时,到底做出了哪些不像 AI 能做的应用? 2026 年 6 月 9 日,Anthropic 放出了 Fable 5。 6 月 12 日,它被暂停访问。 中间只有 72 小时。 就这 72 小时,网上冒出一批很奇怪的东西。 比如只看游戏截图,通关了《Pokémon
( 6
min )
从文件复制这个小场景深挖Java I/O设计哲学:字符缓冲流适合文本但会损坏二进制数据,字节缓冲流才是万能方案。对比两种流的本质差异、缓冲区大小对性能的影响,以及NIO零拷贝的延伸思考。附完整代码示例和实战选型原则。
( 2
min )
拆解 Coding Agent 从 Prompt 到 Loop 的系统化改造:触发、隔离、验证、状态和人工闸门。 原文链接:AI 小老六 导语 过去一段时间,很多人使用 Coding Agent 的方式其实还停留在"远程结对":把需求写清楚,补一段上下文,等它返回结果,再继续追问。这个办法有用,但杠
( 2
min )
Fable 5 被关停前 72 小时,到底做出了哪些不像 AI 能做的应用? 2026 年 6 月 9 日,Anthropic 放出了 Fable 5。 6 月 12 日,它被暂停访问。 中间只有 72 小时。 就这 72 小时,网上冒出一批很奇怪的东西。 比如只看游戏截图,通关了《Pokémon
( 6
min )
从文件复制这个小场景深挖Java I/O设计哲学:字符缓冲流适合文本但会损坏二进制数据,字节缓冲流才是万能方案。对比两种流的本质差异、缓冲区大小对性能的影响,以及NIO零拷贝的延伸思考。附完整代码示例和实战选型原则。
( 2
min )
 本文从技术趋势深度解读视角,解析 MAF 1.0 的五层架构设计、核心理念演化、关键 API 差异、开放协议集成以及 BUILD 2026 最新动态,为 .NET 开发者和 AI 技术从业者提供一份完整的迁移认知地图
( 5
min )
本文从技术趋势深度解读视角,解析 MAF 1.0 的五层架构设计、核心理念演化、关键 API 差异、开放协议集成以及 BUILD 2026 最新动态,为 .NET 开发者和 AI 技术从业者提供一份完整的迁移认知地图
( 5
min )
 Khan Academy disclosed a bug submitted by farr: https://hackerone.com/reports/3723458
Khan Academy disclosed a bug submitted by farr: https://hackerone.com/reports/3723458
Khan Academy disclosed a bug submitted by farr: https://hackerone.com/reports/3723458
Khan Academy disclosed a bug submitted by farr: https://hackerone.com/reports/3723458
 2026 年 6 月 17 日,Vercel 发布了开源 Agent 框架 Eve。官方给它的定位很直接:像 Next.js 之于 Web 应用一样,Eve 想给 Agent 提供一套约定明确、可直接进入生产环境的框架。但它真正想解决的,并不是「怎么再写一个 Agent Loop」,而是 Agent
( 3
min )
2026 年 6 月 17 日,Vercel 发布了开源 Agent 框架 Eve。官方给它的定位很直接:像 Next.js 之于 Web 应用一样,Eve 想给 Agent 提供一套约定明确、可直接进入生产环境的框架。但它真正想解决的,并不是「怎么再写一个 Agent Loop」,而是 Agent
( 3
min )
 stock-sdk 历经 18 个 v1 版本、门面类膨胀至 105 个扁平 getXxx 后,于 v2 推倒重来:API 收拢为命名空间,subpath 支持按需 tree-shaking,数据契约与 SdkError 统一,normalizeSymbol 收敛符号格式,CLI/MCP/Playg...
( 3
min )
本文主要介绍了结构化数据库与缓存中的 IndexedDB、Cache storage 和 Storage buckets,以及期间的区别,供参考。
( 5
min )
缘起 前阵子翻出一台老的便携 DVD 播放器,发现里面居然有游戏菜单。七个分类,80 多款游戏。查了一下发现这东西叫 Native32,凌阳科技的芯片方案,2005-2011 年间大量用在 DVD 播放器和车载显示器上。 游戏由 Potatoo Multimedia Studio 开发,格式是私有的
( 4
min )
Python 打包成 EXE 并非易事,Nuitka 虽然性能卓越,但也隐藏着不少“暗雷”。本文基于 Meta Assistant 的开发实践,解决了 Nuitka `sys.executable` 未能检测是否已打包、CI 构建失败 `FATAL: Nuitka does not work in ...
( 2
min )
HagiCode 中 AI 提交使用的提示词:设计思路与实现拆解 当你把一堆乱七八糟的改动丢给 AI 让它帮你提交时,背后到底发了一段什么样的提示词给模型?为什么提示词要写成那个样子?这篇文章把 HagiCode 里真正驱动"AI 提交"的提示词拆给你看。 背景 用 AI 辅助开发这事,其实也算是经
( 3
min )
换电脑后如何无缝延续 AI 辅助开发?一份手把手的迁移手册,涵盖原理、方案与避坑细节。 目录 一、为什么要迁移会话? 二、先搞懂 Claude Code 把数据存哪了 路径编码规则(非常重要) 三、两种迁移方案 方案 A:相同路径(最简单) 方案 B:路径不同(通用方案) 实战场景 迁移包结构 四、
( 3
min )
一、引言 Loop Engineering 这个词最近又热起来了。 如果你从去年开始关注 AI 工程化领域的动态,大概已经习惯了这种概念迭代的节奏——Prompt Engineering 还没完全消化,Context Engineering 就登场了;Harness Engineering 的论文刚
( 4
min )
stock-sdk 历经 18 个 v1 版本、门面类膨胀至 105 个扁平 getXxx 后,于 v2 推倒重来:API 收拢为命名空间,subpath 支持按需 tree-shaking,数据契约与 SdkError 统一,normalizeSymbol 收敛符号格式,CLI/MCP/Playg...
( 3
min )
本文主要介绍了结构化数据库与缓存中的 IndexedDB、Cache storage 和 Storage buckets,以及期间的区别,供参考。
( 5
min )
缘起 前阵子翻出一台老的便携 DVD 播放器,发现里面居然有游戏菜单。七个分类,80 多款游戏。查了一下发现这东西叫 Native32,凌阳科技的芯片方案,2005-2011 年间大量用在 DVD 播放器和车载显示器上。 游戏由 Potatoo Multimedia Studio 开发,格式是私有的
( 4
min )
Python 打包成 EXE 并非易事,Nuitka 虽然性能卓越,但也隐藏着不少“暗雷”。本文基于 Meta Assistant 的开发实践,解决了 Nuitka `sys.executable` 未能检测是否已打包、CI 构建失败 `FATAL: Nuitka does not work in ...
( 2
min )
HagiCode 中 AI 提交使用的提示词:设计思路与实现拆解 当你把一堆乱七八糟的改动丢给 AI 让它帮你提交时,背后到底发了一段什么样的提示词给模型?为什么提示词要写成那个样子?这篇文章把 HagiCode 里真正驱动"AI 提交"的提示词拆给你看。 背景 用 AI 辅助开发这事,其实也算是经
( 3
min )
换电脑后如何无缝延续 AI 辅助开发?一份手把手的迁移手册,涵盖原理、方案与避坑细节。 目录 一、为什么要迁移会话? 二、先搞懂 Claude Code 把数据存哪了 路径编码规则(非常重要) 三、两种迁移方案 方案 A:相同路径(最简单) 方案 B:路径不同(通用方案) 实战场景 迁移包结构 四、
( 3
min )
一、引言 Loop Engineering 这个词最近又热起来了。 如果你从去年开始关注 AI 工程化领域的动态,大概已经习惯了这种概念迭代的节奏——Prompt Engineering 还没完全消化,Context Engineering 就登场了;Harness Engineering 的论文刚
( 4
min )
 一、前言 作为一名普通开发人员,我对 AI 工具的上手其实算比较晚。今年五月以前,基本还只是把 AI 当作聊天机器人使用。有时听同事提到一些关键词都听不懂,甚至不知道该如何提问,心里多少有些惭愧。直到最近因为一个契机,沉下心认真摸索了一段时间,才真正感受到 AI 工具的魅力和强大,也切身体会到它对生
( 2
min )
LLM具有固化的知识,而且针对LLM的调用是完全无状态,永远只做一锤子买卖。但是交给Agent的任务基本上不可能一蹴而就,而且还希望Agent具有学习进化的能力。所以你会发现,很多的Harness手段的目的就是为了弥合两者之间的鸿沟。解决这个问题的基本的前提是:需要赋予Agent记忆。
( 5
min )
一、前言 作为一名普通开发人员,我对 AI 工具的上手其实算比较晚。今年五月以前,基本还只是把 AI 当作聊天机器人使用。有时听同事提到一些关键词都听不懂,甚至不知道该如何提问,心里多少有些惭愧。直到最近因为一个契机,沉下心认真摸索了一段时间,才真正感受到 AI 工具的魅力和强大,也切身体会到它对生
( 2
min )
LLM具有固化的知识,而且针对LLM的调用是完全无状态,永远只做一锤子买卖。但是交给Agent的任务基本上不可能一蹴而就,而且还希望Agent具有学习进化的能力。所以你会发现,很多的Harness手段的目的就是为了弥合两者之间的鸿沟。解决这个问题的基本的前提是:需要赋予Agent记忆。
( 5
min )
 AI创造是大规模模式重组:文本靠自回归预测,图像靠扩散从噪声还原,代码靠Code LLM学习千万仓库。DeepSeekV4编程成本1美元,Suno文字生成歌曲。AI不知何为美但见过足够美,所以能生成美。
( 1
min )
TokenJuice 的解决方案也足够优雅——不引入额外的 LLM 调用,不牺牲确定性,不增加外部依赖,用静态规则 + 流水线处理,在 < 5ms 内完成 50%-95% 的压缩。Fail-open 的设计哲学、三层规则配置体系、NativeAOT 兼容性,都体现了对生产环境的深刻理解。
( 4
min )
AI创造是大规模模式重组:文本靠自回归预测,图像靠扩散从噪声还原,代码靠Code LLM学习千万仓库。DeepSeekV4编程成本1美元,Suno文字生成歌曲。AI不知何为美但见过足够美,所以能生成美。
( 1
min )
TokenJuice 的解决方案也足够优雅——不引入额外的 LLM 调用,不牺牲确定性,不增加外部依赖,用静态规则 + 流水线处理,在 < 5ms 内完成 50%-95% 的压缩。Fail-open 的设计哲学、三层规则配置体系、NativeAOT 兼容性,都体现了对生产环境的深刻理解。
( 4
min )
 上一篇我们把现代大模型的五个核心模块拼回了 LLaMA 这个完整案例中,可以看到注意力机制仍然是计算最密集的部分。 而这个密集程度在序列变长时,会变得越来越恐怖: 标准自注意力的计算复杂度和空间复杂度都是 \(O(n^2)\):序列长度翻倍,计算量翻四倍,内存占用也翻四倍。 而在之前,我们用 KV
( 4
min )
上周一,我们组的会议纪要还要靠小陈手工整理,开完一个小时的早会,她要再花 40 分钟敲完发出来。同一天,她旁边的同事开完会直接站起来去喝咖啡,3 分钟后纪要已经在群里了。 不是谁效率高低的问题,是用没用对工具的问题。 我在后端做了 10 年,最近两个季度把职场 AI 工具摸了个遍。今天把我们实际跑通
( 2
min )
上一篇我们把现代大模型的五个核心模块拼回了 LLaMA 这个完整案例中,可以看到注意力机制仍然是计算最密集的部分。 而这个密集程度在序列变长时,会变得越来越恐怖: 标准自注意力的计算复杂度和空间复杂度都是 \(O(n^2)\):序列长度翻倍,计算量翻四倍,内存占用也翻四倍。 而在之前,我们用 KV
( 4
min )
上周一,我们组的会议纪要还要靠小陈手工整理,开完一个小时的早会,她要再花 40 分钟敲完发出来。同一天,她旁边的同事开完会直接站起来去喝咖啡,3 分钟后纪要已经在群里了。 不是谁效率高低的问题,是用没用对工具的问题。 我在后端做了 10 年,最近两个季度把职场 AI 工具摸了个遍。今天把我们实际跑通
( 2
min )
 DeepSeek能帮你解数学题、改合同、读文献,但它给出的答案里可能充斥着信誓旦旦但子虚乌有的事实和引用,这源于其推理能力的根本局限。
( 1
min )
DeepSeek能帮你解数学题、改合同、读文献,但它给出的答案里可能充斥着信誓旦旦但子虚乌有的事实和引用,这源于其推理能力的根本局限。
( 1
min )
 If you have an Apple device running iOS 18 or iOS 26 and gone looking for the old Get Verification Code option under Settings → [user name] → Sign-In & Security, you’ve probably noticed it’s no longer there. A quick search turns up forum threads, support comments, and even GitHub issues all reaching the same […]
( 6
min )
在 OCI 上创建测试主机时,明明给启动盘分配了 200G,但进入系统后执行 df -h,根目录却只有 30G 左右。这种情况并不是磁盘没有分配成功,而是分区和 LVM 还没有把剩余空间用起来。 01 | 先看 200G 到底在不在 笔者环境中,df -h 看到的是文件系统大小: /dev/mapp
( 2
min )
If you have an Apple device running iOS 18 or iOS 26 and gone looking for the old Get Verification Code option under Settings → [user name] → Sign-In & Security, you’ve probably noticed it’s no longer there. A quick search turns up forum threads, support comments, and even GitHub issues all reaching the same […]
( 6
min )
在 OCI 上创建测试主机时,明明给启动盘分配了 200G,但进入系统后执行 df -h,根目录却只有 30G 左右。这种情况并不是磁盘没有分配成功,而是分区和 LVM 还没有把剩余空间用起来。 01 | 先看 200G 到底在不在 笔者环境中,df -h 看到的是文件系统大小: /dev/mapp
( 2
min )
 OpenClaw.NET 的 Goal 机制代表了一种重要的工程思路:与其试图训练模型"不要偷懒",不如在运行时层面为 Agent 装上"导航系统"。
( 5
min )
OpenClaw.NET 的 Goal 机制代表了一种重要的工程思路:与其试图训练模型"不要偷懒",不如在运行时层面为 Agent 装上"导航系统"。
( 5
min )
 本文以 Rockchip RK3576/3588 + stmmac + IgH 为例,重点解析 TSN 在 EtherCAT 主站中的应用。针对 EtherCAT 发送抖动受 OS调度制约的痛点,讲清如何用 TSN 的 EST 门控与 Launch Time 把每帧发送时刻下沉到网卡 PHC硬件,实...
( 8
min )
本文以 Rockchip RK3576/3588 + stmmac + IgH 为例,重点解析 TSN 在 EtherCAT 主站中的应用。针对 EtherCAT 发送抖动受 OS调度制约的痛点,讲清如何用 TSN 的 EST 门控与 Launch Time 把每帧发送时刻下沉到网卡 PHC硬件,实...
( 8
min )
 【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 (6) Rollout 目录【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 (6) Rollout0x00 概要0x01 Rollout基础1.1 概念1.1.1 标准 R
( 6
min )
本工作提出全新强化学习框架BeautyGRPO。实验证明,BeautyGRPO 在真实场景的肌肤纹理重建与整体审美对齐上,全面超越了现有的专精修图方法与通用编辑大模型。
( 2
min )
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 (6) Rollout 目录【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 (6) Rollout0x00 概要0x01 Rollout基础1.1 概念1.1.1 标准 R
( 6
min )
本工作提出全新强化学习框架BeautyGRPO。实验证明,BeautyGRPO 在真实场景的肌肤纹理重建与整体审美对齐上,全面超越了现有的专精修图方法与通用编辑大模型。
( 2
min )
 在2.34移除了hook函数之后,堆利用就少了一个大的攻击方向了。而House of apple这个手法就给我们提供了新的攻击方向:IOFILE结构体。虽然在house of orange就有所利用,之后也有一些利用了相关结构体的手法,但都没有House of apple条件简单。 House of
( 8
min )
Openai Codex 重大更新 已支持接入任意开源大模型 如果你还认为 Codex(OpenAI 推出的 AI 编程助手)只能搭配 GPT 系列模型使用,那你可能错过了近期最重要的一次更新。 Codex CLI 现在已经全面支持 OSS 模式(Open-Source Mode),任何兼容 Ope
( 3
min )
在2.34移除了hook函数之后,堆利用就少了一个大的攻击方向了。而House of apple这个手法就给我们提供了新的攻击方向:IOFILE结构体。虽然在house of orange就有所利用,之后也有一些利用了相关结构体的手法,但都没有House of apple条件简单。 House of
( 8
min )
Openai Codex 重大更新 已支持接入任意开源大模型 如果你还认为 Codex(OpenAI 推出的 AI 编程助手)只能搭配 GPT 系列模型使用,那你可能错过了近期最重要的一次更新。 Codex CLI 现在已经全面支持 OSS 模式(Open-Source Mode),任何兼容 Ope
( 3
min )
 本文由袋鼠云数栈 UED 团队分享。文章详细拆解了如何通过 Spec-First 工作流与 AGENTS.md 基础设施,让 AI 从“猜需求”转向“按方案精准编码”,教你用清晰的意图表达彻底释放 AI 的编程潜力。
( 3
min )
本文由袋鼠云数栈 UED 团队分享。文章详细拆解了如何通过 Spec-First 工作流与 AGENTS.md 基础设施,让 AI 从“猜需求”转向“按方案精准编码”,教你用清晰的意图表达彻底释放 AI 的编程潜力。
( 3
min )
 昨天有个客户反馈,在一台Win10电脑上运行 傲瑞通(OrayTalk),结果点击联系人时,右边的聊天窗口始终出不来。现象如下图所示: 一. 问题排查 于是,我们远程到客户的这台电脑上,发现这台电脑有装企业防水墙(驱动级自动文件加密),并且傲瑞通的日志内容有如下报错记录: System.Drawin
( 1
min )
一、那个叫做"知识库"的数字坟场 先说一个你可能亲历过的场景—— 公司花了三个月搭了个知识库。Confluence 也好,飞书文档也好,SharePoint 也好。大家热血沸腾地上传制度文件、项目复盘、销售话术、产品 PRD。搜索框静静躺在页面顶部,仿佛只要它在,知识就在。半年后没人更新了。一年后搜
( 2
min )
昨天有个客户反馈,在一台Win10电脑上运行 傲瑞通(OrayTalk),结果点击联系人时,右边的聊天窗口始终出不来。现象如下图所示: 一. 问题排查 于是,我们远程到客户的这台电脑上,发现这台电脑有装企业防水墙(驱动级自动文件加密),并且傲瑞通的日志内容有如下报错记录: System.Drawin
( 1
min )
一、那个叫做"知识库"的数字坟场 先说一个你可能亲历过的场景—— 公司花了三个月搭了个知识库。Confluence 也好,飞书文档也好,SharePoint 也好。大家热血沸腾地上传制度文件、项目复盘、销售话术、产品 PRD。搜索框静静躺在页面顶部,仿佛只要它在,知识就在。半年后没人更新了。一年后搜
( 2
min )
 一转眼 5 年过去了。今天对我来说同样是具有里程碑意义的日子,一个大客户经过长达近 3 个月的评估,测试,终于签单了。过程十分辛苦,甚至一度让我有点想放弃。
( 1
min )
本文主要介绍了「媒体补充增强信息(SEI)」的基础接入流程,并结合官方文档梳理了环境准备、核心 API 调用、媒体处理和结果验证等关键环节。
( 3
min )
一、架构选型与规划 1.1 高可用主备架构方案 企业级GitLab高可用部署主要有以下几种主流方案: 方案一:DRBD + Pacemaker + Corosync(主备模式) 该架构为Active/Passive(主/备)模式,只有主节点运行GitLab服务并挂载存储,备节点通过DRBD实时同步数
( 5
min )
Electron 应用如何上架微软商店:从 MSIX 打包到商店提交 其实 Electron 说到底,不过是个普普通通的 Win32 桌面应用罢了,可微软商店它只认 MSIX。这篇文章,就借着我们 HagiCode Desktop 实打实跑通的那套构建配置,把「注册开发者账号 → 打 MSIX 包
( 3
min )
gt-checksum v4.0.0 新功能解读(3):反向回滚 SQL
✅ 一键开启 genRollSQL=ON,修复 SQL 自动生成反向回滚操作
✅ DELETE→INSERT、INSERT→DELETE、TRUNCATE 三种映射策略,覆盖全场景
✅ 回滚 SQL 只写文件不在线...
( 4
min )
一转眼 5 年过去了。今天对我来说同样是具有里程碑意义的日子,一个大客户经过长达近 3 个月的评估,测试,终于签单了。过程十分辛苦,甚至一度让我有点想放弃。
( 1
min )
本文主要介绍了「媒体补充增强信息(SEI)」的基础接入流程,并结合官方文档梳理了环境准备、核心 API 调用、媒体处理和结果验证等关键环节。
( 3
min )
一、架构选型与规划 1.1 高可用主备架构方案 企业级GitLab高可用部署主要有以下几种主流方案: 方案一:DRBD + Pacemaker + Corosync(主备模式) 该架构为Active/Passive(主/备)模式,只有主节点运行GitLab服务并挂载存储,备节点通过DRBD实时同步数
( 5
min )
Electron 应用如何上架微软商店:从 MSIX 打包到商店提交 其实 Electron 说到底,不过是个普普通通的 Win32 桌面应用罢了,可微软商店它只认 MSIX。这篇文章,就借着我们 HagiCode Desktop 实打实跑通的那套构建配置,把「注册开发者账号 → 打 MSIX 包
( 3
min )
gt-checksum v4.0.0 新功能解读(3):反向回滚 SQL
✅ 一键开启 genRollSQL=ON,修复 SQL 自动生成反向回滚操作
✅ DELETE→INSERT、INSERT→DELETE、TRUNCATE 三种映射策略,覆盖全场景
✅ 回滚 SQL 只写文件不在线...
( 4
min )
 拆解 Hermes 如何把执行轨迹沉淀为技能、记忆和自修复闭环,让 Agent 真正积累经验。 原文链接:AI 小老六 导语 很多 Agent 产品有一个尴尬的问题:它们看起来每天都在工作,实际上每天都从零开始。 用户让它处理第 1 个复杂任务时,它会试错;第 20 次遇到类似任务时,它还在试错;到
( 2
min )
拆解 Hermes 如何把执行轨迹沉淀为技能、记忆和自修复闭环,让 Agent 真正积累经验。 原文链接:AI 小老六 导语 很多 Agent 产品有一个尴尬的问题:它们看起来每天都在工作,实际上每天都从零开始。 用户让它处理第 1 个复杂任务时,它会试错;第 20 次遇到类似任务时,它还在试错;到
( 2
min )
 MiniMax-M3 是 MiniMax 最新开源的原生多模态大模型,约428B 总参数/23B激活参数,原生支持1M上下文。本文基于 GPUStack 与VLLM,演示从镜像与权重准备、模型部署、对话实测到基准测试的完整流程,并实测了基于 EAGLE3 的投机解码加速。
( 3
min )
NineData 社区版 V5.1.0 这次更新,核心还是围绕 AI 数据库运维能力继续升级。ChatDBA 新增支持类 PostgreSQL、Oracle 和 SQL Server 数据库的全链路性能诊断,SQL 智能优化继续扩到十多种数据库,SQL 执行与任务 Skill 及对应 OpenAPI...
( 2
min )
做软件测试的朋友都清楚,测试用例设计有多么重要。它直接决定了测试覆盖是否全面,也直接影响了后续整体测试流程的质量。 传统模式下,大家手动一条一条编写用例,不仅耗时费力,还经常因为考虑不周,漏掉异常场景、边界条件,给线上质量埋下隐患。 如今借助 AI + Agent Skill 能力,我们可以把用例设
( 3
min )
Skills针对Agent的重要性是不言而喻的。从本质上讲,Agent Skills就是随着用户与LLM对话的推进,动态加载被称为Skill作为提示词的一种机制。在大部分实现中,Skill的内容会被封装成角色为Tool的消息被添加到对话历史中,因为这样可以借助针对对话历史的压缩实现对老旧Skill的...
( 10
min )
MiniMax-M3 是 MiniMax 最新开源的原生多模态大模型,约428B 总参数/23B激活参数,原生支持1M上下文。本文基于 GPUStack 与VLLM,演示从镜像与权重准备、模型部署、对话实测到基准测试的完整流程,并实测了基于 EAGLE3 的投机解码加速。
( 3
min )
NineData 社区版 V5.1.0 这次更新,核心还是围绕 AI 数据库运维能力继续升级。ChatDBA 新增支持类 PostgreSQL、Oracle 和 SQL Server 数据库的全链路性能诊断,SQL 智能优化继续扩到十多种数据库,SQL 执行与任务 Skill 及对应 OpenAPI...
( 2
min )
做软件测试的朋友都清楚,测试用例设计有多么重要。它直接决定了测试覆盖是否全面,也直接影响了后续整体测试流程的质量。 传统模式下,大家手动一条一条编写用例,不仅耗时费力,还经常因为考虑不周,漏掉异常场景、边界条件,给线上质量埋下隐患。 如今借助 AI + Agent Skill 能力,我们可以把用例设
( 3
min )
Skills针对Agent的重要性是不言而喻的。从本质上讲,Agent Skills就是随着用户与LLM对话的推进,动态加载被称为Skill作为提示词的一种机制。在大部分实现中,Skill的内容会被封装成角色为Tool的消息被添加到对话历史中,因为这样可以借助针对对话历史的压缩实现对老旧Skill的...
( 10
min )
 Agent 跑起来之后,大多数时候我们希望它一气呵成把活干完。但总有些场景不太一样——比如 Agent 要调用一个会删文件的工具,你总得让人确认一下再动手吧?LangGraph 的 interrupt 机制就是干这个的:在指定节点前或节点后暂停执行,等人给了信号再接着跑。 动画视频在《28. Age
( 2
min )
Agent 跑起来之后,大多数时候我们希望它一气呵成把活干完。但总有些场景不太一样——比如 Agent 要调用一个会删文件的工具,你总得让人确认一下再动手吧?LangGraph 的 interrupt 机制就是干这个的:在指定节点前或节点后暂停执行,等人给了信号再接着跑。 动画视频在《28. Age
( 2
min )
 当Transformer架构让AI能‘同时看到’整段文字,理解其中的讽刺与隐喻时,语言处理已不再只是识别,而是真正的语义理解。
( 1
min )
当Transformer架构让AI能‘同时看到’整段文字,理解其中的讽刺与隐喻时,语言处理已不再只是识别,而是真正的语义理解。
( 1
min )
 Node.js disclosed a bug submitted by pimterry: https://hackerone.com/reports/3658225
Node.js disclosed a bug submitted by suul: https://hackerone.com/reports/3692858
Node.js disclosed a bug submitted by pimterry: https://hackerone.com/reports/3658225
Node.js disclosed a bug submitted by suul: https://hackerone.com/reports/3692858
接上一篇文章OpenClaw.NET 上线 MetaSkills :软件工程第一性原理的工业级实践, 本篇文章是 MetaSkills 系统深度解析 —— 当 AI 不仅能执行任务,还能编排任务、创造任务,这意味着什么? 一个让工程师崩溃的早晨 想象一下这个场景: 周一早上 9 点,你打开公司内部的
( 6
min )
〇、前言 虽然在日常口语中我们常把浏览器中 Application -> Storage 模块中的多种类型统称为“浏览器缓存”,但在计算机科学与 Web 开发的专业定义中,实际上包含了“存储”与“缓存”两个截然不同但又紧密相关的概念体系。 其中本文将着重介绍的 Local storage 和 Ses
( 4
min )
Node.js disclosed a bug submitted by pimterry: https://hackerone.com/reports/3658225
Node.js disclosed a bug submitted by suul: https://hackerone.com/reports/3692858
Node.js disclosed a bug submitted by pimterry: https://hackerone.com/reports/3658225
Node.js disclosed a bug submitted by suul: https://hackerone.com/reports/3692858
接上一篇文章OpenClaw.NET 上线 MetaSkills :软件工程第一性原理的工业级实践, 本篇文章是 MetaSkills 系统深度解析 —— 当 AI 不仅能执行任务,还能编排任务、创造任务,这意味着什么? 一个让工程师崩溃的早晨 想象一下这个场景: 周一早上 9 点,你打开公司内部的
( 6
min )
〇、前言 虽然在日常口语中我们常把浏览器中 Application -> Storage 模块中的多种类型统称为“浏览器缓存”,但在计算机科学与 Web 开发的专业定义中,实际上包含了“存储”与“缓存”两个截然不同但又紧密相关的概念体系。 其中本文将着重介绍的 Local storage 和 Ses
( 4
min )
 统计时间:2026 年 6 月 3 日下午 15 点至 19 点。 一、先说结论 推测: (1)在五小时计费周期内,最大可消耗 18 美元的额度和 4000 万 Token(使用 Sonnet 模型)。 (2)每周有 10 个五小时计费周期,最大可消耗 180 美元的额度和 4 亿 Token(使用
( 2
min )
Electron 如何调用 Windows 原生 API 在 Electron 应用里调用 Windows 原生 API,就像想看海却只能看地图。不过折腾了一阵,总算摸索出几条路,写下这篇文章算是留个纪念,也给后来者指个方向。 背景 做 Electron 桌面应用的时候,难免要和操作系统打打交道。在
( 3
min )
OpenStack 1.7.2 & Ceph 9.2.1 运维命令,加载认证文件,实例管理,服务状态检查,计算服务 (Nova),网络服务 (Neutron),存储服务 (Cinder),集群整体资源概况,计算节点维护,RabbitMQ 连通性测试,Keystone 项目管理,RAID 检查,软件 ...
( 6
min )
统计时间:2026 年 6 月 3 日下午 15 点至 19 点。 一、先说结论 推测: (1)在五小时计费周期内,最大可消耗 18 美元的额度和 4000 万 Token(使用 Sonnet 模型)。 (2)每周有 10 个五小时计费周期,最大可消耗 180 美元的额度和 4 亿 Token(使用
( 2
min )
Electron 如何调用 Windows 原生 API 在 Electron 应用里调用 Windows 原生 API,就像想看海却只能看地图。不过折腾了一阵,总算摸索出几条路,写下这篇文章算是留个纪念,也给后来者指个方向。 背景 做 Electron 桌面应用的时候,难免要和操作系统打打交道。在
( 3
min )
OpenStack 1.7.2 & Ceph 9.2.1 运维命令,加载认证文件,实例管理,服务状态检查,计算服务 (Nova),网络服务 (Neutron),存储服务 (Cinder),集群整体资源概况,计算节点维护,RabbitMQ 连通性测试,Keystone 项目管理,RAID 检查,软件 ...
( 6
min )
 拆解 AI 产品输出从文本到工作台的协议分层:Markdown 写文档,HTML 承载页面,UI DSL 接住操作。 原文链接:AI 小老六 导语 最近不少 AI 产品开始把回答做得越来越"像页面":有卡片、有筛选器、有图表,也有可点击操作。于是一个问题被反复拿出来讨论:HTML 会不会替代 Ma
( 2
min )
作为最核心的AIAgent,`ChatClientAgent`构建了一个管道与LLM交互。为了让管道的输出更符合我们的需求,有两个主要的途径:输入增强(Input Enhancement)和输出增强(Output Enhancement),前者通过通过改变输入让LLM返回更高质量的内容,后者则直接对...
( 4
min )
拆解 AI 产品输出从文本到工作台的协议分层:Markdown 写文档,HTML 承载页面,UI DSL 接住操作。 原文链接:AI 小老六 导语 最近不少 AI 产品开始把回答做得越来越"像页面":有卡片、有筛选器、有图表,也有可点击操作。于是一个问题被反复拿出来讨论:HTML 会不会替代 Ma
( 2
min )
作为最核心的AIAgent,`ChatClientAgent`构建了一个管道与LLM交互。为了让管道的输出更符合我们的需求,有两个主要的途径:输入增强(Input Enhancement)和输出增强(Output Enhancement),前者通过通过改变输入让LLM返回更高质量的内容,后者则直接对...
( 4
min )
 世界杯进球被吹?背后是VAR+AI的精密协作:摄像机追踪29个身体点、球内传感器锁定传球瞬间、AI自动生成越位线与3D动画,再经VAR复核、主裁终裁。AI负责“测得准”,裁判负责“判得明”——技术让判罚更透明,却未消除规则语境下的争议。
( 1
min )
世界杯进球被吹?背后是VAR+AI的精密协作:摄像机追踪29个身体点、球内传感器锁定传球瞬间、AI自动生成越位线与3D动画,再经VAR复核、主裁终裁。AI负责“测得准”,裁判负责“判得明”——技术让判罚更透明,却未消除规则语境下的争议。
( 1
min )
 Agent和具身智能,一个扎根在虚拟世界里替你跑任务,一个走进物理世界替你动手操作。这篇文章,我们来聊聊这两条AI执行能力进化的核心路径。
( 1
min )
Agent和具身智能,一个扎根在虚拟世界里替你跑任务,一个走进物理世界替你动手操作。这篇文章,我们来聊聊这两条AI执行能力进化的核心路径。
( 1
min )
 HackerOne disclosed a bug submitted by brumbelow: https://hackerone.com/reports/3694007 - Bounty: $7000
HackerOne disclosed a bug submitted by brumbelow: https://hackerone.com/reports/3694007 - Bounty: $7000
 curl disclosed a bug submitted by argareksapatii: https://hackerone.com/reports/3802645
HackerOne disclosed a bug submitted by brumbelow: https://hackerone.com/reports/3694007 - Bounty: $7000
curl disclosed a bug submitted by argareksapatii: https://hackerone.com/reports/3802645
当系统平稳运行时,你是发号施令的架构师,驾驭 LLM 和云原生框架在宏观上狂奔。但当服务器在深夜崩溃,当 AI 给出的解释全是指鹿为马的幻觉时,你必须有能力瞬间推开抽象的胡言乱语,化身成底层机器的同类——读十六进制内存快照,抓 TCP 报文头部,在无数死锁的线程栈里,徒手掐死那只 bug。
这,才...
( 2
min )
Electron 桌面应用如何接入 Microsoft Store 订阅与永久许可证 当你的 Electron 应用要进 Microsoft Store 卖订阅和永久授权,WinRT 那一套商业 API 到底怎么干净地接到业务里?这事儿说起来也算一桩旧梦,我们在 HagiCode Desktop 里
( 4
min )
curl disclosed a bug submitted by argareksapatii: https://hackerone.com/reports/3802645
HackerOne disclosed a bug submitted by brumbelow: https://hackerone.com/reports/3694007 - Bounty: $7000
curl disclosed a bug submitted by argareksapatii: https://hackerone.com/reports/3802645
当系统平稳运行时,你是发号施令的架构师,驾驭 LLM 和云原生框架在宏观上狂奔。但当服务器在深夜崩溃,当 AI 给出的解释全是指鹿为马的幻觉时,你必须有能力瞬间推开抽象的胡言乱语,化身成底层机器的同类——读十六进制内存快照,抓 TCP 报文头部,在无数死锁的线程栈里,徒手掐死那只 bug。
这,才...
( 2
min )
Electron 桌面应用如何接入 Microsoft Store 订阅与永久许可证 当你的 Electron 应用要进 Microsoft Store 卖订阅和永久授权,WinRT 那一套商业 API 到底怎么干净地接到业务里?这事儿说起来也算一桩旧梦,我们在 HagiCode Desktop 里
( 4
min )
 问题描述 在 Azure AI Search 中搜索 in brief 时,结果数量有时会比预期多很多。仔细查看返回结果文本,会发现有些文档和 brief 的关系很弱,反而只是命中了 in 这类高频词。 这不是数据问题,也不是 Azure AI Search 的 bug。关键在于一个很容易被忽略的地
( 2
min )
问题描述 在 Azure AI Search 中搜索 in brief 时,结果数量有时会比预期多很多。仔细查看返回结果文本,会发现有些文档和 brief 的关系很弱,反而只是命中了 in 这类高频词。 这不是数据问题,也不是 Azure AI Search 的 bug。关键在于一个很容易被忽略的地
( 2
min )
 【Agentic RL / 强化学习框架】Miles 项目技术分析 (2) 关键技术 目录【Agentic RL / 强化学习框架】Miles 项目技术分析 (2) 关键技术0x00 概要0x01 agentic_tool_call1.1 问题1.2 解决方案1.3 框架自动化的主要流水线1.4 深
( 17
min )
【Agentic RL / 强化学习框架】Miles 项目技术分析 (2) 关键技术 目录【Agentic RL / 强化学习框架】Miles 项目技术分析 (2) 关键技术0x00 概要0x01 agentic_tool_call1.1 问题1.2 解决方案1.3 框架自动化的主要流水线1.4 深
( 17
min )
 拆解 GEPA 如何用轨迹反馈、Pareto 前沿和模块合并,让 Prompt 优化更稳、更可审计。 原文链接:AI 小老六 Agent 系统里的 Prompt 很少是一次写对的。更常见的情况是,线上 case 出错以后,人去翻日志、看工具调用、读模型输出,再手工改一版 Prompt 或 Skill
( 3
min )
拆解 GEPA 如何用轨迹反馈、Pareto 前沿和模块合并,让 Prompt 优化更稳、更可审计。 原文链接:AI 小老六 Agent 系统里的 Prompt 很少是一次写对的。更常见的情况是,线上 case 出错以后,人去翻日志、看工具调用、读模型输出,再手工改一版 Prompt 或 Skill
( 3
min )
 16GB 内存又爆了,任务管理器又在关键时刻死活打不开?渲染、测试时总是担心 OOM 导致系统崩溃?Memory Checker 是一款专为 Windows 打造的极致轻量开源托盘控件。仅 15MB 安装包,通过实时变色的托盘图标,让你对内存占用“一眼定心”,告别死机焦虑。
( 1
min )
16GB 内存又爆了,任务管理器又在关键时刻死活打不开?渲染、测试时总是担心 OOM 导致系统崩溃?Memory Checker 是一款专为 Windows 打造的极致轻量开源托盘控件。仅 15MB 安装包,通过实时变色的托盘图标,让你对内存占用“一眼定心”,告别死机焦虑。
( 1
min )
 原文链接:https://www.nocobase.com/cn/blog/future-of-software-programmers-revenue-doubled 前情 半年前,我们在 NocoBase 发布 2.0 的时候写过第二篇总结文章:《没有 AI,没有融资,一个开源项目的真实收入》,
( 2
min )
在自动化报表生成与数据处理场景中,数值的展示方式直接影响文档的可读性与专业性。千分位分隔、货币符号、百分比显示、日期格式化等效果,均通过 Excel 的数字格式机制实现。本文将介绍如何通过 Python 代码精确控制 Excel 单元格的数字显示格式,示例基于 Free Spire.XLS for
( 2
min )
原文链接:https://www.nocobase.com/cn/blog/future-of-software-programmers-revenue-doubled 前情 半年前,我们在 NocoBase 发布 2.0 的时候写过第二篇总结文章:《没有 AI,没有融资,一个开源项目的真实收入》,
( 2
min )
在自动化报表生成与数据处理场景中,数值的展示方式直接影响文档的可读性与专业性。千分位分隔、货币符号、百分比显示、日期格式化等效果,均通过 Excel 的数字格式机制实现。本文将介绍如何通过 Python 代码精确控制 Excel 单元格的数字显示格式,示例基于 Free Spire.XLS for
( 2
min )
 前言 本文主要描述Event-Driven开发中的ReAct模式,并且使用一个demo,彻底搞懂怎么在实际工作中使用Event-Driven模式 话不多说,我们开始 代码结构 代码地址 . ├── agent.py # EventDrivenAgent 主逻辑,负责接收事件、调用 LLM、执行工具
( 2
min )
前言 本文主要描述Event-Driven开发中的ReAct模式,并且使用一个demo,彻底搞懂怎么在实际工作中使用Event-Driven模式 话不多说,我们开始 代码结构 代码地址 . ├── agent.py # EventDrivenAgent 主逻辑,负责接收事件、调用 LLM、执行工具
( 2
min )
 一边,模型和开发者工具还在继续往真实工作流里走:Gemini 3.5 Live Translate 开始做近实时语音翻译,Kimi-K2.7-Code 开源,DiffusionGemma 探索更快的文本生成,Codex 和 Chrome DevTools 也在继续给 Agent 补浏览器能力。
另一...
( 3
min )
将YF3300-ESP32S3设备数据上传到叶帆物联网平台需要使用 YFLink 协议通过 MQTT 进行通信。本章以完整项目 YeFanIoTTest 为例,介绍从设备初始化到数据上传的完整实现。
( 46
min )
curl disclosed a bug submitted by newstuff321: https://hackerone.com/reports/3804525
一边,模型和开发者工具还在继续往真实工作流里走:Gemini 3.5 Live Translate 开始做近实时语音翻译,Kimi-K2.7-Code 开源,DiffusionGemma 探索更快的文本生成,Codex 和 Chrome DevTools 也在继续给 Agent 补浏览器能力。
另一...
( 3
min )
将YF3300-ESP32S3设备数据上传到叶帆物联网平台需要使用 YFLink 协议通过 MQTT 进行通信。本章以完整项目 YeFanIoTTest 为例,介绍从设备初始化到数据上传的完整实现。
( 46
min )
curl disclosed a bug submitted by newstuff321: https://hackerone.com/reports/3804525
 Rocket.Chat disclosed a bug submitted by eldudareeno: https://hackerone.com/reports/3611837
Rocket.Chat disclosed a bug submitted by eldudareeno: https://hackerone.com/reports/3611837
 Tor disclosed a bug submitted by aptupdate: https://hackerone.com/reports/3701692 - Bounty: $100
curl disclosed a bug submitted by newstuff321: https://hackerone.com/reports/3804525
Rocket.Chat disclosed a bug submitted by eldudareeno: https://hackerone.com/reports/3611837
Tor disclosed a bug submitted by aptupdate: https://hackerone.com/reports/3701692 - Bounty: $100
Rocket.Chat disclosed a bug submitted by aikido_security: https://hackerone.com/reports/3687142
Tor disclosed a bug submitted by aptupdate: https://hackerone.com/reports/3701692 - Bounty: $100
curl disclosed a bug submitted by newstuff321: https://hackerone.com/reports/3804525
Rocket.Chat disclosed a bug submitted by eldudareeno: https://hackerone.com/reports/3611837
Tor disclosed a bug submitted by aptupdate: https://hackerone.com/reports/3701692 - Bounty: $100
Rocket.Chat disclosed a bug submitted by aikido_security: https://hackerone.com/reports/3687142
 IBM disclosed a bug submitted by entrovyx: https://hackerone.com/reports/3664261
curl disclosed a bug submitted by unknowperson0212: https://hackerone.com/reports/3793495
curl disclosed a bug submitted by daviey: https://hackerone.com/reports/3803415
Rocket.Chat disclosed a bug submitted by aikido_security: https://hackerone.com/reports/3687142
IBM disclosed a bug submitted by entrovyx: https://hackerone.com/reports/3664261
curl disclosed a bug submitted by unknowperson0212: https://hackerone.com/reports/3793495
curl disclosed a bug submitted by daviey: https://hackerone.com/reports/3803415
IBM disclosed a bug submitted by entrovyx: https://hackerone.com/reports/3664261
curl disclosed a bug submitted by unknowperson0212: https://hackerone.com/reports/3793495
curl disclosed a bug submitted by daviey: https://hackerone.com/reports/3803415
Rocket.Chat disclosed a bug submitted by aikido_security: https://hackerone.com/reports/3687142
IBM disclosed a bug submitted by entrovyx: https://hackerone.com/reports/3664261
curl disclosed a bug submitted by unknowperson0212: https://hackerone.com/reports/3793495
curl disclosed a bug submitted by daviey: https://hackerone.com/reports/3803415
 问题描述 在 Azure AI Search 里,英文检索有时会卡在一个很小的词形差异上:文档里是 brief,搜索 briefs 却搜不到。 搜索 briefs,无法命中只包含 brief 的文档。类似地,audit 和 auditing 也可能因为一个复数形式导致结果不同。 文档明明在,关键词也
( 2
min )
问题描述 在 Azure AI Search 里,英文检索有时会卡在一个很小的词形差异上:文档里是 brief,搜索 briefs 却搜不到。 搜索 briefs,无法命中只包含 brief 的文档。类似地,audit 和 auditing 也可能因为一个复数形式导致结果不同。 文档明明在,关键词也
( 2
min )
 【Agentic RL / 强化学习框架】Miles 项目技术分析 (1) 总体 目录【Agentic RL / 强化学习框架】Miles 项目技术分析 (1) 总体0x00 概要0x01 基础1.1 Agentic RL 的需求与难点1.1.1 传统 RLHF vs Agentic RL 范式对比
( 12
min )
【Agentic RL / 强化学习框架】Miles 项目技术分析 (1) 总体 目录【Agentic RL / 强化学习框架】Miles 项目技术分析 (1) 总体0x00 概要0x01 基础1.1 Agentic RL 的需求与难点1.1.1 传统 RLHF vs Agentic RL 范式对比
( 12
min )
 这次用 Codex 读 Typer,最重要的一点是:面对一个新项目,第一步先别急着让它写代码。比较稳妥的做法,是先让 Codex 读目录、找入口、解释核心文件,再沿着一个具体功能追下去,最后通过测试理解项目如何验证行为。
( 3
min )
前两天刷知乎的时候,看到一个很有意思的帖子,标题叫:《面试官问:你用 AI 编程半年了,那怎么保证 Claude Code 写出来的代码是对的?》 翻完评论区,我没有找到特别满意的答案,反而越发有感触。 借着这个话题,今天来简单聊聊。 不知道正在看文章的你,还记不记得自己第一次体验 Vibe Cod
( 2
min )
这次用 Codex 读 Typer,最重要的一点是:面对一个新项目,第一步先别急着让它写代码。比较稳妥的做法,是先让 Codex 读目录、找入口、解释核心文件,再沿着一个具体功能追下去,最后通过测试理解项目如何验证行为。
( 3
min )
前两天刷知乎的时候,看到一个很有意思的帖子,标题叫:《面试官问:你用 AI 编程半年了,那怎么保证 Claude Code 写出来的代码是对的?》 翻完评论区,我没有找到特别满意的答案,反而越发有感触。 借着这个话题,今天来简单聊聊。 不知道正在看文章的你,还记不记得自己第一次体验 Vibe Cod
( 2
min )
 拆解 Workflow Runtime 如何用代码接管 Agent Loop,让长任务更稳定、可复盘、可复用。 原文链接:AI 小老六 导语 过去一两年,很多人都在想同一个问题:Agent 为什么一到长任务就开始飘? 单轮问答里,模型很聪明。给它一个目标、几条约束、几个工具,它经常能给出不错的结果。
( 3
min )
拆解 Workflow Runtime 如何用代码接管 Agent Loop,让长任务更稳定、可复盘、可复用。 原文链接:AI 小老六 导语 过去一两年,很多人都在想同一个问题:Agent 为什么一到长任务就开始飘? 单轮问答里,模型很聪明。给它一个目标、几条约束、几个工具,它经常能给出不错的结果。
( 3
min )
 一个能让后端开发效率翻倍的“自动构建工坊”长什么样? 先说点掏心窝子的话做后端开发的朋友都知道,每个项目启动时,我们都在重复做同一件事: 建表 → 写实体类 → 写Repository → 写Service → 写Controller → 写Swagger注解 → 写数据库文档 → ... 一套流程
( 1
min )
先前我们基于React实现了视图层的适配,以此实现React组件生态的复用,降低了开发成本。接下来我们需要讨论的是,编辑器的操作管理并且支持回溯,通常来说可以称之为Redo/Undo功能,而在协同编辑场景下,本地和远程变更同步的实现会更加复杂。 开源地址: https://github.com/Wi
( 4
min )
一个能让后端开发效率翻倍的“自动构建工坊”长什么样? 先说点掏心窝子的话做后端开发的朋友都知道,每个项目启动时,我们都在重复做同一件事: 建表 → 写实体类 → 写Repository → 写Service → 写Controller → 写Swagger注解 → 写数据库文档 → ... 一套流程
( 1
min )
先前我们基于React实现了视图层的适配,以此实现React组件生态的复用,降低了开发成本。接下来我们需要讨论的是,编辑器的操作管理并且支持回溯,通常来说可以称之为Redo/Undo功能,而在协同编辑场景下,本地和远程变更同步的实现会更加复杂。 开源地址: https://github.com/Wi
( 4
min )
 三个月前,我把从各路博客扒来的 Skills 一股脑装进 ~/.claude/skills/,总共 34 个。 效果怎样?说实话,Claude Code 确实变聪明了一些——但也开始变慢,有时候明明只是问个代码问题,它会莫名其妙地触发一堆不相关的 Skill,token 飞速消耗。最夸张的一次,一个
( 3
min )
大家好,我是小林。 如果你在准备 2026 的 AI 岗面试,先把这个网站收藏了: 小林面试笔记:https://xiaolinnote.com 专注 AI Agent 开发方向的面试题网站,图解 Agent + RAG + LLM 面试题,让一部分人先跑赢 AI Agent 开发面试。 为什
( 3
min )
Spring、MyBatis如何在运行时动态创建对象和调用方法?答案就是Java反射。本文从实际困惑出发,用代码实战讲解反射核心API,揭秘框架底层原理,并分析反射的性能代价与使用建议。
( 2
min )
一份现代知识系统的全景地图 PKM、RAG、Wiki、AI 记忆系统,以及如今实用的 AI 辅助工作流,常常被放在一起讨论,仿佛它们解决的是同一个问题。事实并非如此。它们都与知识有关,但运作在不同层面: PKM 帮助人类思考。 Wiki 帮助团队保存共享知识。 RAG 帮助机器检索外部知识。 记忆系
( 3
min )
很多人第一次接触AI Agent,会有一种类似"读医学教材"的困惑:单词都认识,但读完不知道在讲什么。 "规划"、"记忆"、"工具调用"、"ReAct框架"……这些词经常一起出现,但彼此的关系说不清楚,看起来像是四套不同系统硬拼在一起。 这篇文章,我想把这四个东西的逻辑关系说透。它们不是并列的,更不
( 2
min )
Modbus Studio (免费的Modbus主从机软件) 1. 软件用途 Modbus Studio 是一个用于 Modbus RTU / Modbus TCP 调试的桌面工具,主要用于: 作为 Client 连接真实设备并读取、写入点位。 作为 Server 模拟从站,供其他主站软件或设备读取
( 5
min )
当工具在执行过程借助注入对话历史的消息来描述当前的情况,以辅助LLM后续能够更加精准的推理,这是非常有价值的。比如工具在执行过程中发现验证的风控风险,可以注入一条`Assistant`消息模拟LLM的回复来提示用户风险的存在。
( 3
min )
三个月前,我把从各路博客扒来的 Skills 一股脑装进 ~/.claude/skills/,总共 34 个。 效果怎样?说实话,Claude Code 确实变聪明了一些——但也开始变慢,有时候明明只是问个代码问题,它会莫名其妙地触发一堆不相关的 Skill,token 飞速消耗。最夸张的一次,一个
( 3
min )
大家好,我是小林。 如果你在准备 2026 的 AI 岗面试,先把这个网站收藏了: 小林面试笔记:https://xiaolinnote.com 专注 AI Agent 开发方向的面试题网站,图解 Agent + RAG + LLM 面试题,让一部分人先跑赢 AI Agent 开发面试。 为什
( 3
min )
Spring、MyBatis如何在运行时动态创建对象和调用方法?答案就是Java反射。本文从实际困惑出发,用代码实战讲解反射核心API,揭秘框架底层原理,并分析反射的性能代价与使用建议。
( 2
min )
一份现代知识系统的全景地图 PKM、RAG、Wiki、AI 记忆系统,以及如今实用的 AI 辅助工作流,常常被放在一起讨论,仿佛它们解决的是同一个问题。事实并非如此。它们都与知识有关,但运作在不同层面: PKM 帮助人类思考。 Wiki 帮助团队保存共享知识。 RAG 帮助机器检索外部知识。 记忆系
( 3
min )
很多人第一次接触AI Agent,会有一种类似"读医学教材"的困惑:单词都认识,但读完不知道在讲什么。 "规划"、"记忆"、"工具调用"、"ReAct框架"……这些词经常一起出现,但彼此的关系说不清楚,看起来像是四套不同系统硬拼在一起。 这篇文章,我想把这四个东西的逻辑关系说透。它们不是并列的,更不
( 2
min )
Modbus Studio (免费的Modbus主从机软件) 1. 软件用途 Modbus Studio 是一个用于 Modbus RTU / Modbus TCP 调试的桌面工具,主要用于: 作为 Client 连接真实设备并读取、写入点位。 作为 Server 模拟从站,供其他主站软件或设备读取
( 5
min )
当工具在执行过程借助注入对话历史的消息来描述当前的情况,以辅助LLM后续能够更加精准的推理,这是非常有价值的。比如工具在执行过程中发现验证的风控风险,可以注入一条`Assistant`消息模拟LLM的回复来提示用户风险的存在。
( 3
min )
 有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
( 1
min )
本文记录作者第一次将 Vibe Coding 开发的 Next.js + NestJS 全栈项目部署到生产环境的完整过程。由于 Vercel 不适合托管 Node.js 后端,作者选择阿里云 Windows Server 作为服务器,使用 PM2 守护 NestJS 进程,配合 Caddy 反向代理...
( 4
min )
有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
( 1
min )
本文记录作者第一次将 Vibe Coding 开发的 Next.js + NestJS 全栈项目部署到生产环境的完整过程。由于 Vercel 不适合托管 Node.js 后端,作者选择阿里云 Windows Server 作为服务器,使用 PM2 守护 NestJS 进程,配合 Caddy 反向代理...
( 4
min )
 AI语音助手,目前逐渐开始成为主流手机品牌的标准功能。你有没有想过:在你对手机说"帮我定个明天早上八点的闹钟",手机是怎么听懂的?
( 1
min )
从 Prompt 到 Loop:理清 AI Agent 工程的概念演进 前言 如果你最近关注 AI Agent 领域,一定被各种新术语轰炸过:Prompt Engineering、Context Engineering、Harness Engineering、Loop Engineering……这些
( 12
min )
AI语音助手,目前逐渐开始成为主流手机品牌的标准功能。你有没有想过:在你对手机说"帮我定个明天早上八点的闹钟",手机是怎么听懂的?
( 1
min )
从 Prompt 到 Loop:理清 AI Agent 工程的概念演进 前言 如果你最近关注 AI Agent 领域,一定被各种新术语轰炸过:Prompt Engineering、Context Engineering、Harness Engineering、Loop Engineering……这些
( 12
min )
 上周,一个朋友在群里发了一张截图:GitHub 上 anthropics/skills 仓库,24 小时涨了 900 颗星。 他的原话是:「一个文件夹项目,13.6 万星?这是认真的吗?」 我点开一看,确实——这个仓库的核心内容就是一堆 SKILL.md 文件,外加几个 Python 脚本。没有炫酷
( 6
min )
上周,一个朋友在群里发了一张截图:GitHub 上 anthropics/skills 仓库,24 小时涨了 900 颗星。 他的原话是:「一个文件夹项目,13.6 万星?这是认真的吗?」 我点开一看,确实——这个仓库的核心内容就是一堆 SKILL.md 文件,外加几个 Python 脚本。没有炫酷
( 6
min )
 2026 FIFA 世界杯开赛,周末一边看一边VIBE搭了一个纯静态、无后端的实时数据看板,开源在 GitHub。 在线体验: https://skyseraph.github.io/world-cup-2026/ 先看一下效果 它能做什么 3D 地球仪:48 支参赛队标注在地球上,按小组着色,点击
( 2
min )
引言 在 .NET 开发中,生成 HTML 内容是一个常见的需求。无论是构建邮件模板、生成报表、还是创建动态网页内容,我们都需要一种简洁、安全且高效的方式来构建 HTML。今天,我想向大家介绍 Jasmine.Format —— 一个专为高性能场景设计的 .NET HTML 生成库。 为什么需要 J
( 3
min )
引言:那些年我们写过的“面条代码” 痛点场景: 你一定经历过这样的噩梦:系统最初用 MySQL 存储数据,后来为了性能要迁移到 MongoDB。结果你发现,业务代码里密密麻麻全是对 MySQL 驱动的直接调用。或者,老板突发奇想,要求把原本的 Web 页面功能,原封不动地搬到一个新的命令行工具(CL
( 2
min )
深入剖析了在 Huawei P30 (鸿蒙 4.0)上解决 Unity 原生库 RELRO 装载异常的完整排查路径,通过优化链接器标志、策略性使用静态库及规范符号导出,为鸿蒙系统下的底层兼容性问题提供了切实可行的解决方案。
( 5
min )
Zenith.NET 最近做了一轮比较大的 RHI 重构。它不是一次普通的 API 改名,也不是单纯整理代码,而是把整个图形抽象层从早期“更容易上手的封装”,往更现代、更贴近 DirectX 12 / Vulkan / Metal 的底层模型推进。 这轮重构的重点,是新版引入了哪些能力、为什么要做
( 3
min )
2026 FIFA 世界杯开赛,周末一边看一边VIBE搭了一个纯静态、无后端的实时数据看板,开源在 GitHub。 在线体验: https://skyseraph.github.io/world-cup-2026/ 先看一下效果 它能做什么 3D 地球仪:48 支参赛队标注在地球上,按小组着色,点击
( 2
min )
引言 在 .NET 开发中,生成 HTML 内容是一个常见的需求。无论是构建邮件模板、生成报表、还是创建动态网页内容,我们都需要一种简洁、安全且高效的方式来构建 HTML。今天,我想向大家介绍 Jasmine.Format —— 一个专为高性能场景设计的 .NET HTML 生成库。 为什么需要 J
( 3
min )
引言:那些年我们写过的“面条代码” 痛点场景: 你一定经历过这样的噩梦:系统最初用 MySQL 存储数据,后来为了性能要迁移到 MongoDB。结果你发现,业务代码里密密麻麻全是对 MySQL 驱动的直接调用。或者,老板突发奇想,要求把原本的 Web 页面功能,原封不动地搬到一个新的命令行工具(CL
( 2
min )
深入剖析了在 Huawei P30 (鸿蒙 4.0)上解决 Unity 原生库 RELRO 装载异常的完整排查路径,通过优化链接器标志、策略性使用静态库及规范符号导出,为鸿蒙系统下的底层兼容性问题提供了切实可行的解决方案。
( 5
min )
Zenith.NET 最近做了一轮比较大的 RHI 重构。它不是一次普通的 API 改名,也不是单纯整理代码,而是把整个图形抽象层从早期“更容易上手的封装”,往更现代、更贴近 DirectX 12 / Vulkan / Metal 的底层模型推进。 这轮重构的重点,是新版引入了哪些能力、为什么要做
( 3
min )
 Agent 通过 Checkpointer 记住对话上下文不是什么难事,但要是想让它存点“业务数据”——比如用户偏好、任务进度、历史操作记录这类东西——光靠 Checkpointer 就有点力不从心了。对话线程之间彼此隔离,换个线程就像失忆一样,之前积累的信息全用不上。Store 机制就是来解决这个
( 2
min )
Agent 通过 Checkpointer 记住对话上下文不是什么难事,但要是想让它存点“业务数据”——比如用户偏好、任务进度、历史操作记录这类东西——光靠 Checkpointer 就有点力不从心了。对话线程之间彼此隔离,换个线程就像失忆一样,之前积累的信息全用不上。Store 机制就是来解决这个
( 2
min )
 传统SOP依赖人工监督、人工核验,存在监管滞后、人工成本高、漏检误检等痛点。依托iNeuOS_Vision机器视觉技术,可实现SOP操作的自动化识别、实时监测、流程校验与异常告警,适配各类工业标准化作业场景,助力工业作业全流程可视化、智能化管控,提升生产标准化水平与作业效率。
( 1
min )
Speed Tools:一套低侵入的 Android 插件化 + 动态换肤 + 字体切换框架 作者:一航 GitHub:jasonliyihang/speed_tools 博客首发于 CSDN,本文基于 2026 年最新代码重构整理。 一、前言 几年前我在 CSDN 写过一篇 [《android 插
( 3
min )
传统SOP依赖人工监督、人工核验,存在监管滞后、人工成本高、漏检误检等痛点。依托iNeuOS_Vision机器视觉技术,可实现SOP操作的自动化识别、实时监测、流程校验与异常告警,适配各类工业标准化作业场景,助力工业作业全流程可视化、智能化管控,提升生产标准化水平与作业效率。
( 1
min )
Speed Tools:一套低侵入的 Android 插件化 + 动态换肤 + 字体切换框架 作者:一航 GitHub:jasonliyihang/speed_tools 博客首发于 CSDN,本文基于 2026 年最新代码重构整理。 一、前言 几年前我在 CSDN 写过一篇 [《android 插
( 3
min )
 从数据中寻找规律的机器学习,到模仿人脑思考的深度学习,再到让机器看懂世界的计算机视觉,这三项技术共同构建了人工智能最底层也最核心的逻辑框架。
( 1
min )
curl disclosed a bug submitted by violet12331: https://hackerone.com/reports/3795615
curl disclosed a bug submitted by violet12331: https://hackerone.com/reports/3795615
DDD 与 Ontology 对比分析:代码建模与语义建模的异同 探讨领域驱动设计(DDD)与本体论建模(Ontology)之间的本质差异,搞清其背后的理论体系和运行机制。 一、双维建模:逻辑深度与语义广度 复杂业务系统的建模方法与开发方式可以分为两条路线: DDD 范式:以应用代码开发为主,利用充
( 4
min )
一句话认识这个工具 在做数据采集或调用第三方API时,经常需要从嵌套复杂的JSON中提取指定数据。今天给大家安利一个免费在线工具——JSON Path Finder,地址是 https://formatlist.com/json-path-finder。 先直接看效果:把JSON数据粘贴进去,它会自
( 2
min )
从数据中寻找规律的机器学习,到模仿人脑思考的深度学习,再到让机器看懂世界的计算机视觉,这三项技术共同构建了人工智能最底层也最核心的逻辑框架。
( 1
min )
curl disclosed a bug submitted by violet12331: https://hackerone.com/reports/3795615
curl disclosed a bug submitted by violet12331: https://hackerone.com/reports/3795615
DDD 与 Ontology 对比分析:代码建模与语义建模的异同 探讨领域驱动设计(DDD)与本体论建模(Ontology)之间的本质差异,搞清其背后的理论体系和运行机制。 一、双维建模:逻辑深度与语义广度 复杂业务系统的建模方法与开发方式可以分为两条路线: DDD 范式:以应用代码开发为主,利用充
( 4
min )
一句话认识这个工具 在做数据采集或调用第三方API时,经常需要从嵌套复杂的JSON中提取指定数据。今天给大家安利一个免费在线工具——JSON Path Finder,地址是 https://formatlist.com/json-path-finder。 先直接看效果:把JSON数据粘贴进去,它会自
( 2
min )
 它能做什么? 简单说:让你的电脑自动帮你干活。 批量点击、填表、截图 → 告别重复劳动 定时执行任务 → 每天自动签到、自动导出报表 图像识别 + 自动化 → 找到屏幕上的按钮自动点 AI 一句话生成 → "在坐标500,300点击,输入hello按回车" 直接变成自动化流程 为什么值得关注? 1.
( 2
min )
它能做什么? 简单说:让你的电脑自动帮你干活。 批量点击、填表、截图 → 告别重复劳动 定时执行任务 → 每天自动签到、自动导出报表 图像识别 + 自动化 → 找到屏幕上的按钮自动点 AI 一句话生成 → "在坐标500,300点击,输入hello按回车" 直接变成自动化流程 为什么值得关注? 1.
( 2
min )
 按照之前文章《氛围编程实战系列:先规划清楚学习路径》这个规划路径,我们今天来开发第二个功能:合并知识功能。 总结这篇文章的初期阶段,其实让笔者非常的困惑。因为经历了太多思想碰撞。最终认为如果要持续学习一件新事物,还必须要从现实出发,不要为了学习而学习,而要为了解决一个实际问题而学习,哪怕这个问题开始
( 2
min )
按照之前文章《氛围编程实战系列:先规划清楚学习路径》这个规划路径,我们今天来开发第二个功能:合并知识功能。 总结这篇文章的初期阶段,其实让笔者非常的困惑。因为经历了太多思想碰撞。最终认为如果要持续学习一件新事物,还必须要从现实出发,不要为了学习而学习,而要为了解决一个实际问题而学习,哪怕这个问题开始
( 2
min )
 很多独立开发者在产品刚做出来的时候,都会下意识想到 Product Hunt 或 Hacker News。 这并不奇怪。对一个没有用户、没有品牌、没有媒体资源的小团队来说,把产品发到一个已经聚集了大量产品爱好者和技术人群的平台上,听起来几乎是最合理的选择。那里有人愿意点开新产品,有人愿意评论,有人会
( 2
min )
⚠️ 安全警告:混沌工程工具威力巨大。Toxiproxy 仅限于开发、测试(SIT/UAT)或特定的混沌工程演练环境中使用。严禁将其部署在生产环境的真实业务链路中,以免造成不可挽回的生产资损与事故。 在微服务架构和系统可观测性建设中,验证各链路的容错与兜底机制(Error-handling fail
( 2
min )
还在为团队文档维护头疼吗?本文带你认识一个极简却强大的文档神器docsify,无需编译、一个页面搞定一切。从安装配置到避坑指南,手把手教你搭建一个高颜值、易维护的知识库网站,让你的技术文档管理体验瞬间起飞。
( 2
min )
很多独立开发者在产品刚做出来的时候,都会下意识想到 Product Hunt 或 Hacker News。 这并不奇怪。对一个没有用户、没有品牌、没有媒体资源的小团队来说,把产品发到一个已经聚集了大量产品爱好者和技术人群的平台上,听起来几乎是最合理的选择。那里有人愿意点开新产品,有人愿意评论,有人会
( 2
min )
⚠️ 安全警告:混沌工程工具威力巨大。Toxiproxy 仅限于开发、测试(SIT/UAT)或特定的混沌工程演练环境中使用。严禁将其部署在生产环境的真实业务链路中,以免造成不可挽回的生产资损与事故。 在微服务架构和系统可观测性建设中,验证各链路的容错与兜底机制(Error-handling fail
( 2
min )
还在为团队文档维护头疼吗?本文带你认识一个极简却强大的文档神器docsify,无需编译、一个页面搞定一切。从安装配置到避坑指南,手把手教你搭建一个高颜值、易维护的知识库网站,让你的技术文档管理体验瞬间起飞。
( 2
min )
 作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 背景 最近在测试一个服务器的时候,遇到一个难题:我如何才能构造出多种请求,以便尽可能的覆盖到所有分支? 写单元测试固然是个办法,但是服务器依赖 mysql 和
( 2
min )
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 背景 最近在测试一个服务器的时候,遇到一个难题:我如何才能构造出多种请求,以便尽可能的覆盖到所有分支? 写单元测试固然是个办法,但是服务器依赖 mysql 和
( 2
min )
 很多团队已经有 APM 了。 Java 服务接了 SkyWalking,云上应用用了 ARMS,部分云原生团队接了 Jaeger,新项目开始按 OpenTelemetry 做链路追踪。慢接口、错误调用、服务拓扑、Trace 瀑布图,也都能看。 所以当有人再提“统一可观测平台”时,团队会有一个很自然的
( 2
min )
很多团队已经有 APM 了。 Java 服务接了 SkyWalking,云上应用用了 ARMS,部分云原生团队接了 Jaeger,新项目开始按 OpenTelemetry 做链路追踪。慢接口、错误调用、服务拓扑、Trace 瀑布图,也都能看。 所以当有人再提“统一可观测平台”时,团队会有一个很自然的
( 2
min )
 星辰征途是一家聚焦 AI 搜索与电商场景多模态 AIGC 应用的初创公司,成立两年多,业务主要面向海外市场。公司目前的主要产品包括:Gensmo(gensmo.com) 聚焦时尚穿搭,提供虚拟试穿、造型推荐和商品搜索;ZooClaw(zooclaw.ai) 面向更广泛的生活与工作场景,提供 AI A
( 3
min )
很多团队一谈到数据库审计,第一反应就是“把所有 SQL 都记下来”。仿佛日志越全,安全感越足。可真到出事的时候,却发现自己面对的只是海量文本,根本不知道从何查起。真正有价值的数据库审计,必须能够清晰回答四个问题: 谁做了高风险操作? 针对哪个库、哪张表、哪些数据做的? 这个动作是否越权、异常或违反流
( 2
min )
本文基于 0xkato 的英文文章 "How LLMs Actually Work" 改写整理,用于中文读者学习参考。 原文:https://www.0xkato.xyz/how-llms-actually-work 标签:Machine Learning · Transformers · LLM
( 4
min )
上周我在 Claude Code 里说了一句:「帮我把今天的站会纪要发到研发群」。 Claude 很流畅地组织好了内容,然后调用 lark-cli 发送。在它真的发出去之前,终端里打出了一段 dry-run 预览——消息体、目标群组 ID、发送时间,全部清清楚楚列在屏幕上,等我确认。 我看了一眼,发
( 4
min )
Claude Code 配置第三方模型后,内置工具到底用的谁的? 核心问题:Claude Code 配了智谱(Z.AI)的 key 后,WebSearch、图片分析、web_fetch 这些能力,是用的 Claude/Anthropic 原生的,还是被替换成了 GLM 的? 结论:全部用的是智谱的
( 3
min )
星辰征途是一家聚焦 AI 搜索与电商场景多模态 AIGC 应用的初创公司,成立两年多,业务主要面向海外市场。公司目前的主要产品包括:Gensmo(gensmo.com) 聚焦时尚穿搭,提供虚拟试穿、造型推荐和商品搜索;ZooClaw(zooclaw.ai) 面向更广泛的生活与工作场景,提供 AI A
( 3
min )
很多团队一谈到数据库审计,第一反应就是“把所有 SQL 都记下来”。仿佛日志越全,安全感越足。可真到出事的时候,却发现自己面对的只是海量文本,根本不知道从何查起。真正有价值的数据库审计,必须能够清晰回答四个问题: 谁做了高风险操作? 针对哪个库、哪张表、哪些数据做的? 这个动作是否越权、异常或违反流
( 2
min )
本文基于 0xkato 的英文文章 "How LLMs Actually Work" 改写整理,用于中文读者学习参考。 原文:https://www.0xkato.xyz/how-llms-actually-work 标签:Machine Learning · Transformers · LLM
( 4
min )
上周我在 Claude Code 里说了一句:「帮我把今天的站会纪要发到研发群」。 Claude 很流畅地组织好了内容,然后调用 lark-cli 发送。在它真的发出去之前,终端里打出了一段 dry-run 预览——消息体、目标群组 ID、发送时间,全部清清楚楚列在屏幕上,等我确认。 我看了一眼,发
( 4
min )
Claude Code 配置第三方模型后,内置工具到底用的谁的? 核心问题:Claude Code 配了智谱(Z.AI)的 key 后,WebSearch、图片分析、web_fetch 这些能力,是用的 Claude/Anthropic 原生的,还是被替换成了 GLM 的? 结论:全部用的是智谱的
( 3
min )
 Spring Cloud Gateway 的 SpEL 表达式注入漏洞(CVE-2022-22947) 受影响版本 以下版本的 Spring Cloud Gateway 存在此漏洞: 3.1.0 3.0.0 至 3.0.6 以及其他更早的、已停止维护的版本 环境搭建 由于我是在公司电脑(刚入职),所
( 2
min )
Spring Cloud Gateway 的 SpEL 表达式注入漏洞(CVE-2022-22947) 受影响版本 以下版本的 Spring Cloud Gateway 存在此漏洞: 3.1.0 3.0.0 至 3.0.6 以及其他更早的、已停止维护的版本 环境搭建 由于我是在公司电脑(刚入职),所
( 2
min )
 Google AX 的重点不在“再造一个 Agent 框架”,而在补上 控制面、状态恢复、故障隔离、权限审计 这些真正决定生产可用性的工程能力。
( 2
min )
Google AX 的重点不在“再造一个 Agent 框架”,而在补上 控制面、状态恢复、故障隔离、权限审计 这些真正决定生产可用性的工程能力。
( 2
min )
 赋予部署的应用和服务可观测性已经是一个基本的需求,在这方面,`OpenTelemetry`无疑已经称为了事实上的标准。`OpenTelemetryChatClient`是一个预定义的`IChatClient`中间件,它利用重写的`GetResponseAsync`和`GetResponseStrea...
( 2
min )
Node.js disclosed a bug submitted by shinchan_69: https://hackerone.com/reports/3781015
Node.js disclosed a bug submitted by shinchan_69: https://hackerone.com/reports/3781015
curl disclosed a bug submitted by bugthiru: https://hackerone.com/reports/3741744
curl disclosed a bug submitted by fg0x0: https://hackerone.com/reports/3774279
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3383079
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3393664
curl disclosed a bug submitted by bugthiru: https://hackerone.com/reports/3741744
curl disclosed a bug submitted by fg0x0: https://hackerone.com/reports/3774279
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3383079
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3393664
赋予部署的应用和服务可观测性已经是一个基本的需求,在这方面,`OpenTelemetry`无疑已经称为了事实上的标准。`OpenTelemetryChatClient`是一个预定义的`IChatClient`中间件,它利用重写的`GetResponseAsync`和`GetResponseStrea...
( 2
min )
Node.js disclosed a bug submitted by shinchan_69: https://hackerone.com/reports/3781015
Node.js disclosed a bug submitted by shinchan_69: https://hackerone.com/reports/3781015
curl disclosed a bug submitted by bugthiru: https://hackerone.com/reports/3741744
curl disclosed a bug submitted by fg0x0: https://hackerone.com/reports/3774279
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3383079
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3393664
curl disclosed a bug submitted by bugthiru: https://hackerone.com/reports/3741744
curl disclosed a bug submitted by fg0x0: https://hackerone.com/reports/3774279
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3383079
Rocket.Chat disclosed a bug submitted by button142857: https://hackerone.com/reports/3393664
 系统规划与管理师 到底是干嘛的?很多考友尤其是做运维的兄弟,经常在“高项”和“系规”之间纠结。今天咱们就用最直白的大白话,把这个系统规划与管理师拆解开看。建议点赞+收藏,下次报名时可以翻出来了解下。 一、 为什么大家都对“系规”有误解? 很多朋友一听到“系统规划与管理师”,第一反应就是:这不就是个高
( 2
min )
系统规划与管理师 到底是干嘛的?很多考友尤其是做运维的兄弟,经常在“高项”和“系规”之间纠结。今天咱们就用最直白的大白话,把这个系统规划与管理师拆解开看。建议点赞+收藏,下次报名时可以翻出来了解下。 一、 为什么大家都对“系规”有误解? 很多朋友一听到“系统规划与管理师”,第一反应就是:这不就是个高
( 2
min )
 【强化学习框架】Uni-Agent 深度技术分析(2) 关键技术 目录【强化学习框架】Uni-Agent 深度技术分析(2) 关键技术0x00 概要0x01 修改扩展点1.1 verl 扩展点全景1.2 关键扩展点详解E1: AgentLoopBase——继承契约E3: 注册机制——外部注入 vs
( 11
min )
把全量备份的 Kingbase v8 实例备份文件恢复到另外一个实例中 背景介绍: 公司的机房断电!!!虽然离谱但是它就是断电了。导致安装了麒麟V10操作系统的服务器宕机且尝试了几种方式后均无法恢复启动,好在磁盘是完好的。因为是测试服务器,经过评估后选择重装系统。服务器上仅有的比较重要一些的资产是部
( 2
min )
【强化学习框架】Uni-Agent 深度技术分析(2) 关键技术 目录【强化学习框架】Uni-Agent 深度技术分析(2) 关键技术0x00 概要0x01 修改扩展点1.1 verl 扩展点全景1.2 关键扩展点详解E1: AgentLoopBase——继承契约E3: 注册机制——外部注入 vs
( 11
min )
把全量备份的 Kingbase v8 实例备份文件恢复到另外一个实例中 背景介绍: 公司的机房断电!!!虽然离谱但是它就是断电了。导致安装了麒麟V10操作系统的服务器宕机且尝试了几种方式后均无法恢复启动,好在磁盘是完好的。因为是测试服务器,经过评估后选择重装系统。服务器上仅有的比较重要一些的资产是部
( 2
min )
 写代码时总要在每个方法里复制粘贴计时逻辑?本文用匿名内部类实现了一个优雅的耗时计算模板,从"笨办法"到Lambda表达式,一步步优化代码结构,适合想提升代码设计能力的Java学习者。
( 2
min )
引言 在数字化转型加速推进的今天,实时数据仓库已成为企业数据驱动决策的核心基础设施。Apache Doris作为一款高性能、易运维的开源MPP分析型数据库,凭借其极简架构、亚秒级查询响应和一站式分析能力,被广泛应用于用户行为分析、实时报表、数据集市等核心业务场景。然而,随着企业数据量的爆发式增长和查
( 3
min )
写爬虫或调用API时,IP被封是家常便饭。很多人以为加上代理就万事大吉,结果反而更慢、报错更多。这篇文章从实战出发,一次性讲透http、https、socks代理的区别和用法,教你如何高效遍历代理列表,并扒开那些官方文档不会告诉你的常见坑。读完你会知道,代理用不好,比不用还危险。
( 2
min )
写代码时总要在每个方法里复制粘贴计时逻辑?本文用匿名内部类实现了一个优雅的耗时计算模板,从"笨办法"到Lambda表达式,一步步优化代码结构,适合想提升代码设计能力的Java学习者。
( 2
min )
引言 在数字化转型加速推进的今天,实时数据仓库已成为企业数据驱动决策的核心基础设施。Apache Doris作为一款高性能、易运维的开源MPP分析型数据库,凭借其极简架构、亚秒级查询响应和一站式分析能力,被广泛应用于用户行为分析、实时报表、数据集市等核心业务场景。然而,随着企业数据量的爆发式增长和查
( 3
min )
写爬虫或调用API时,IP被封是家常便饭。很多人以为加上代理就万事大吉,结果反而更慢、报错更多。这篇文章从实战出发,一次性讲透http、https、socks代理的区别和用法,教你如何高效遍历代理列表,并扒开那些官方文档不会告诉你的常见坑。读完你会知道,代理用不好,比不用还危险。
( 2
min )
 OpenVINO™ C# API 3.3 全新发布!这次升级的重点,是把 OpenVINO GenAI 正式带进 C#/.NET 生态。开发者可以在 C# 项目中直接调用本地 LLM 文本生成、Whisper 语音识别、VLM 图文问答等能力,不再必须绕 Python 服务或外部脚本。
3.3 继...
( 5
min )
OpenVINO™ C# API 3.3 全新发布!这次升级的重点,是把 OpenVINO GenAI 正式带进 C#/.NET 生态。开发者可以在 C# 项目中直接调用本地 LLM 文本生成、Whisper 语音识别、VLM 图文问答等能力,不再必须绕 Python 服务或外部脚本。
3.3 继...
( 5
min )
 在默认的情况下,`ChatHistoryProvider`基于**调用**对产生的请求和消息进行存档。如果一次调用涉及多轮ReAct循环,意味着每次调用可能会很多条消息,但是它们只会在ReAct循环结束之后才会被存档一次。如果最后存单失败,意味着这些消息将全部丢失,所以有时候我们ReAct循环的每次...
( 3
min )
在默认的情况下,`ChatHistoryProvider`基于**调用**对产生的请求和消息进行存档。如果一次调用涉及多轮ReAct循环,意味着每次调用可能会很多条消息,但是它们只会在ReAct循环结束之后才会被存档一次。如果最后存单失败,意味着这些消息将全部丢失,所以有时候我们ReAct循环的每次...
( 3
min )
 AI 时代,拉开差距的不是工具熟练度,而是在不确定里启动、验证和接力的能力。 原文链接:AI 小老六 我现在越来越不相信一种说法:只要把 AI 工具 用熟,人就会自然变强。 工具当然重要,但它解决的是“怎么做得更快”,没有自动解决“什么值得做”“该从哪里下手”“做砸以后怎么办”。真正拉开差距的,往往
( 2
min )
作为第二篇技术复盘,本文通过弃用 vite-plugin-pwa,改用 $service-worker 解决了 PWA 报错 Uncaught (in promise) non-precached-url: non-precached-url :: [{"url":"index.html"}];添加...
( 1
min )
AI 时代,拉开差距的不是工具熟练度,而是在不确定里启动、验证和接力的能力。 原文链接:AI 小老六 我现在越来越不相信一种说法:只要把 AI 工具 用熟,人就会自然变强。 工具当然重要,但它解决的是“怎么做得更快”,没有自动解决“什么值得做”“该从哪里下手”“做砸以后怎么办”。真正拉开差距的,往往
( 2
min )
作为第二篇技术复盘,本文通过弃用 vite-plugin-pwa,改用 $service-worker 解决了 PWA 报错 Uncaught (in promise) non-precached-url: non-precached-url :: [{"url":"index.html"}];添加...
( 1
min )
 问题描述 在 Azure AI Search 中查询同一组关键词时,经常会遇到一个现象:searchMode=any 返回很多结果,改成 searchMode=all 后结果数量明显下降,甚至只剩很少几条。 例如查询下面这组关键词: audit brief report compliance 如果使
( 2
min )
问题描述 在 Azure AI Search 中查询同一组关键词时,经常会遇到一个现象:searchMode=any 返回很多结果,改成 searchMode=all 后结果数量明显下降,甚至只剩很少几条。 例如查询下面这组关键词: audit brief report compliance 如果使
( 2
min )
 感谢 Snowflake 这次邀请我以 Snowflake 雪花大使身份参加 Snowflake Summit。这次大会给我的触动比预想中更大,大家知道,我一直做从事数据行业,早期在 Teradata,后来在 IBM,后来在企业里 Lenovo、中金、万达等管大数据,后来成为 Apache Soft...
( 3
min )
本文基于如下 Qwen3 配置文件进行讲解: { "architectures": [ "Qwen3ForSequenceClassification" ], "attention_bias": false, "attention_dropout": 0.0, "bos_token_id": 151
( 7
min )
感谢 Snowflake 这次邀请我以 Snowflake 雪花大使身份参加 Snowflake Summit。这次大会给我的触动比预想中更大,大家知道,我一直做从事数据行业,早期在 Teradata,后来在 IBM,后来在企业里 Lenovo、中金、万达等管大数据,后来成为 Apache Soft...
( 3
min )
本文基于如下 Qwen3 配置文件进行讲解: { "architectures": [ "Qwen3ForSequenceClassification" ], "attention_bias": false, "attention_dropout": 0.0, "bos_token_id": 151
( 7
min )
 前言 本文去掉代码全文共 4800 字。 这篇博客并非完全意义上的题解,主要是对我学习这道题的思路回顾与总结,基于以下两篇题解融合和补充(所以记号不是我原创的,我觉得尤其是第二篇题解定义的名词非常形象易懂直接抄了),以及一些碎碎念。 写了很多细节问题,都是我在学习这个题时思考过的,所以这篇文章非常长
( 6
min )
前言 本文去掉代码全文共 4800 字。 这篇博客并非完全意义上的题解,主要是对我学习这道题的思路回顾与总结,基于以下两篇题解融合和补充(所以记号不是我原创的,我觉得尤其是第二篇题解定义的名词非常形象易懂直接抄了),以及一些碎碎念。 写了很多细节问题,都是我在学习这个题时思考过的,所以这篇文章非常长
( 6
min )
 创建型模式关心的核心问题只有一个:对象怎么来的? 把"怎么创建对象"这件事封装起来,让使用者不需要知道细节,拿来就用。
( 9
min )
PDF是日常工作中最常用的文档格式之一。借助 Python,我们可以批量提取 PDF 中的文本、图片、表格等数据,从而实现自动化处理。本文将介绍如何使用 Free Spire.PDF for Python 这个免费库来完成常见的 PDF 读取任务。 1. 环境准备 1.1 安装免费 Python P
( 2
min )
引言:无监控,不运维 在关键信息基础设施安全保障体系中,实时、精准的资源监控是发现性能瓶颈、预防故障的第一道防线。MySQL数据库作为业务数据的承载核心,其CPU和内存的消耗直接决定了服务的吞吐量与稳定性。很多性能故障(如上一篇文章分析的CPU间歇性飙高)若能被及时监控和预警,就完全可以在恶化前被扼
( 2
min )
你有没有这种感受:早上开完站会,拿起手机一看,项目群、运营群、技术交流群——三个群加起来 400 条消息,最重要的那条结论被淹没在表情包和「收到」里面,根本找不着。 我之前每天要花将近 40 分钟翻群——不是认真看,就是怕漏掉什么重要的事。直到我把 wx-cli 和 Claude Code Skil
( 3
min )
SolonCode,基于"Java 运行时 + Web 交互"的架构设计,天然具备跨平台能力。在鸿蒙 PC 发布之初,SolonCode 即可运行。
( 2
min )
创建型模式关心的核心问题只有一个:对象怎么来的? 把"怎么创建对象"这件事封装起来,让使用者不需要知道细节,拿来就用。
( 9
min )
PDF是日常工作中最常用的文档格式之一。借助 Python,我们可以批量提取 PDF 中的文本、图片、表格等数据,从而实现自动化处理。本文将介绍如何使用 Free Spire.PDF for Python 这个免费库来完成常见的 PDF 读取任务。 1. 环境准备 1.1 安装免费 Python P
( 2
min )
引言:无监控,不运维 在关键信息基础设施安全保障体系中,实时、精准的资源监控是发现性能瓶颈、预防故障的第一道防线。MySQL数据库作为业务数据的承载核心,其CPU和内存的消耗直接决定了服务的吞吐量与稳定性。很多性能故障(如上一篇文章分析的CPU间歇性飙高)若能被及时监控和预警,就完全可以在恶化前被扼
( 2
min )
你有没有这种感受:早上开完站会,拿起手机一看,项目群、运营群、技术交流群——三个群加起来 400 条消息,最重要的那条结论被淹没在表情包和「收到」里面,根本找不着。 我之前每天要花将近 40 分钟翻群——不是认真看,就是怕漏掉什么重要的事。直到我把 wx-cli 和 Claude Code Skil
( 3
min )
SolonCode,基于"Java 运行时 + Web 交互"的架构设计,天然具备跨平台能力。在鸿蒙 PC 发布之初,SolonCode 即可运行。
( 2
min )
 我们目前已经有相当专业的图片生成的模型,它可以利用我们提供的文本提示来生成高质量的图片,但是由于我们对文字的驾驭能力不够,写不出迎合LLM的提示词。ImageGeneratingChatClient中间件结合我们注册的ImageGenerator将两者结合在一起:我们通过与Agent对话的方式说出我...
( 6
min )
我们目前已经有相当专业的图片生成的模型,它可以利用我们提供的文本提示来生成高质量的图片,但是由于我们对文字的驾驭能力不够,写不出迎合LLM的提示词。ImageGeneratingChatClient中间件结合我们注册的ImageGenerator将两者结合在一起:我们通过与Agent对话的方式说出我...
( 6
min )
 curl disclosed a bug submitted by monk17: https://hackerone.com/reports/3791168
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3791191
curl disclosed a bug submitted by nyymi: https://hackerone.com/reports/1826392
curl disclosed a bug submitted by monk17: https://hackerone.com/reports/3791168
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3791191
curl disclosed a bug submitted by nyymi: https://hackerone.com/reports/1826392
curl disclosed a bug submitted by monk17: https://hackerone.com/reports/3791168
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3791191
curl disclosed a bug submitted by nyymi: https://hackerone.com/reports/1826392
curl disclosed a bug submitted by monk17: https://hackerone.com/reports/3791168
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3791191
curl disclosed a bug submitted by nyymi: https://hackerone.com/reports/1826392
 I’m doing an experiment with KTP and two lasers (1052nm and 1550nm), this is the first time I try to create some more advanced optic project. Initially I was thinking it was just shining the laser light in the KTP crystal and everything was fine. Then I discovered that I need to use two mirrors … Continue reading Using a Nonlinear Crystal KTP to create a SFG/SHG solution →
( 11
min )
I’m doing an experiment with KTP and two lasers (1052nm and 1550nm), this is the first time I try to create some more advanced optic project. Initially I was thinking it was just shining the laser light in the KTP crystal and everything was fine. Then I discovered that I need to use two mirrors … Continue reading Using a Nonlinear Crystal KTP to create a SFG/SHG solution →
( 11
min )
 Artificial intelligence is not just responding to prompts and generating text anymore. The age of agentic artificial intelligence has arrived. With it comes the ability to think, make decisions, plan and act independently. What Is Agentic AI? While regular AI models just respond to inputs with outputs, an agentic AI system uses APIs, databases, cloud […]
The post Agentic AI Security: The Hidden Attack Surface Beyond Prompt Injection appeared first on Payatu.
( 69
min )
Artificial intelligence is not just responding to prompts and generating text anymore. The age of agentic artificial intelligence has arrived. With it comes the ability to think, make decisions, plan and act independently. What Is Agentic AI? While regular AI models just respond to inputs with outputs, an agentic AI system uses APIs, databases, cloud […]
The post Agentic AI Security: The Hidden Attack Surface Beyond Prompt Injection appeared first on Payatu.
( 69
min )
 The Bug That Turns Security Tools Against Researchers I found a bug in binwalk that lets an attacker write files anywhere on your computer. If you are a security researcher, you have probably used binwalk to pull apart firmware files. It comes pre-installed on Kali Linux. Hundreds of thousands of people use it every day. […]
The post Binwalk Path Traversal Vulnerability: Turning Firmware Analysis into Code Execution appeared first on Payatu.
( 68
min )
The Bug That Turns Security Tools Against Researchers I found a bug in binwalk that lets an attacker write files anywhere on your computer. If you are a security researcher, you have probably used binwalk to pull apart firmware files. It comes pre-installed on Kali Linux. Hundreds of thousands of people use it every day. […]
The post Binwalk Path Traversal Vulnerability: Turning Firmware Analysis into Code Execution appeared first on Payatu.
( 68
min )
 前言 在数字化办公与娱乐需求日益增长的今天,Windows 系统的流畅度与稳定性直接影响着我们的日常体验。为了帮助大家告别系统卡顿、冗余服务以及隐私泄露的困扰,大姚给大家分享 5 款基于 .NET 开源、功能强大且免费的 Windows 系统优化工具。 Optimizer Optimizer 是一款
( 2
min )
大家可以先看本文的结论【即 4. 总结】,如有兴趣再顺读。 1. Online DDL Support for Column Operations OperationIn PlaceRebuilds TablePermits Concurrent DMLOnly Modifies Metadata
( 3
min )
前言 在数字化办公与娱乐需求日益增长的今天,Windows 系统的流畅度与稳定性直接影响着我们的日常体验。为了帮助大家告别系统卡顿、冗余服务以及隐私泄露的困扰,大姚给大家分享 5 款基于 .NET 开源、功能强大且免费的 Windows 系统优化工具。 Optimizer Optimizer 是一款
( 2
min )
大家可以先看本文的结论【即 4. 总结】,如有兴趣再顺读。 1. Online DDL Support for Column Operations OperationIn PlaceRebuilds TablePermits Concurrent DMLOnly Modifies Metadata
( 3
min )
 Meta Assistant 是一个为 Windows 打造的任务栏托盘 Python 脚本启动器,以解决 Vibe Coding 时代下“生成脚本易,寻找脚本难”的困境。安装 Meta Assistant,快速利用本地已有环境启动对应的脚本,并原生支持 Windows 自启动,不再需要在打包、配置...
( 1
min )
Meta Assistant 是一个为 Windows 打造的任务栏托盘 Python 脚本启动器,以解决 Vibe Coding 时代下“生成脚本易,寻找脚本难”的困境。安装 Meta Assistant,快速利用本地已有环境启动对应的脚本,并原生支持 Windows 自启动,不再需要在打包、配置...
( 1
min )
 在最近给一个大客户制作技术方案时,客户提出了一个要求:对他们已经部署测试运行的环境,分析其运行性能数据,并制作分析报告。
( 2
min )
在最近给一个大客户制作技术方案时,客户提出了一个要求:对他们已经部署测试运行的环境,分析其运行性能数据,并制作分析报告。
( 2
min )
 【Agentic RL / 强化学习框架】Uni-Agent 深度技术分析(1) 总体 目录【Agentic RL / 强化学习框架】Uni-Agent 深度技术分析(1) 总体0x00 概要0x01 基本功能1.1 竞品对比与定位1.1.1 三者定位1.1.2 七维度对比表1.2 Uni-Agen
( 14
min )
有一件事我直到用了 Claude Code 三个月才搞清楚—— 它的上下文窗口是 200K tokens,但这个数字在大型代码库里根本撑不了多久。 粗略换算:一个普通 Java 服务文件大约 200-500 行,按每行 10 个 token 计算,200K tokens 大约能容纳 400-1000
( 4
min )
1. 先区分两个概念:多头和多层 Multi-Head Attention 和多层 Transformer Block 不是一回事。 一句话区分: Multi-Head Attention:同一层里,多个 attention head 并行看上下文。 多层 Transformer Block:很多层
( 6
min )
【Agentic RL / 强化学习框架】Uni-Agent 深度技术分析(1) 总体 目录【Agentic RL / 强化学习框架】Uni-Agent 深度技术分析(1) 总体0x00 概要0x01 基本功能1.1 竞品对比与定位1.1.1 三者定位1.1.2 七维度对比表1.2 Uni-Agen
( 14
min )
有一件事我直到用了 Claude Code 三个月才搞清楚—— 它的上下文窗口是 200K tokens,但这个数字在大型代码库里根本撑不了多久。 粗略换算:一个普通 Java 服务文件大约 200-500 行,按每行 10 个 token 计算,200K tokens 大约能容纳 400-1000
( 4
min )
1. 先区分两个概念:多头和多层 Multi-Head Attention 和多层 Transformer Block 不是一回事。 一句话区分: Multi-Head Attention:同一层里,多个 attention head 并行看上下文。 多层 Transformer Block:很多层
( 6
min )
 .NET 是一个开源、跨平台的开发平台,运行稳定,资源消耗低,AOT 编译进一步降低了交付体积。本文基于 .NET 10 实现一个零配置的热重载服务器,核心代码不到 50 行。 依赖安装:dotnet add package PicoServer NuGet:https://www.nuget.or
( 2
min )
.NET 是一个开源、跨平台的开发平台,运行稳定,资源消耗低,AOT 编译进一步降低了交付体积。本文基于 .NET 10 实现一个零配置的热重载服务器,核心代码不到 50 行。 依赖安装:dotnet add package PicoServer NuGet:https://www.nuget.or
( 2
min )
 上一篇我们介绍了 KV Cache:它把每一步重复的 K、V 计算存进缓存,让自回归推理的计算量骤降。 但这个加速不是没有代价的。KV Cache 的大小正比于多项参数,因此又反过来推动了注意力结构本身的改进。 这便是本篇内容:分组查询注意力(Grouped-Query Attention,GQA)
( 3
min )
上一篇我们介绍了 KV Cache:它把每一步重复的 K、V 计算存进缓存,让自回归推理的计算量骤降。 但这个加速不是没有代价的。KV Cache 的大小正比于多项参数,因此又反过来推动了注意力结构本身的改进。 这便是本篇内容:分组查询注意力(Grouped-Query Attention,GQA)
( 3
min )
 你是否曾幻想过,只用一个自然语言指令,AI就能帮你完成从需求分析到代码提交的整个开发流程?现在,这个幻想正通过MonkeyCode变为现实。 什么是MonkeyCode? MonkeyCode是由长亭科技推出的企业级在线AI开发平台,已在GitHub上获得3.2k Star。它不仅仅是一个代码
( 2
min )
你是否曾幻想过,只用一个自然语言指令,AI就能帮你完成从需求分析到代码提交的整个开发流程?现在,这个幻想正通过MonkeyCode变为现实。 什么是MonkeyCode? MonkeyCode是由长亭科技推出的企业级在线AI开发平台,已在GitHub上获得3.2k Star。它不仅仅是一个代码
( 2
min )
 本文基于 2026-06-09 对 OpenDeepWiki 与 AIDotNet/Means 生成页 的一次源码与页面抽检。样本里的生成配置是:目录由 gpt-5.5 生成,正文由 Mimo-2.5 生成;Mimo 侧累计消费约 1.3B token,总成本约 39 RMB,折算约 0.03 RM
( 2
min )
本文基于 2026-06-09 对 OpenDeepWiki 与 AIDotNet/Means 生成页 的一次源码与页面抽检。样本里的生成配置是:目录由 gpt-5.5 生成,正文由 Mimo-2.5 生成;Mimo 侧累计消费约 1.3B token,总成本约 39 RMB,折算约 0.03 RM
( 2
min )
 这两年,AI 编程工具的进化速度非常快。 从最早的代码补全,到现在的 Claude Code、Codex、Cursor、Cline、OpenCode,各类 Agent 已经不只是“帮你写一段函数”了。它们可以读项目、改代码、跑命令、调用工具、分析报错,甚至连续执行一整套开发任务。 这当然很爽。 但问
( 3
min )
这两年,AI 编程工具的进化速度非常快。 从最早的代码补全,到现在的 Claude Code、Codex、Cursor、Cline、OpenCode,各类 Agent 已经不只是“帮你写一段函数”了。它们可以读项目、改代码、跑命令、调用工具、分析报错,甚至连续执行一整套开发任务。 这当然很爽。 但问
( 3
min )
 出色的开发工作有着一套固定节奏:构思、尝试、检查、调整。本月的 Visual Studio 更新便贴合了这套开发节奏。无论您是在修改任何文件前借助 Plan Agent 拟定开发思路,评审多个文件的改动内容,还是精细调校 Copilot 的工作上下文,五月版本更新在从想法落地到修改定稿的过程中增设了
( 2
min )
出色的开发工作有着一套固定节奏:构思、尝试、检查、调整。本月的 Visual Studio 更新便贴合了这套开发节奏。无论您是在修改任何文件前借助 Plan Agent 拟定开发思路,评审多个文件的改动内容,还是精细调校 Copilot 的工作上下文,五月版本更新在从想法落地到修改定稿的过程中增设了
( 2
min )
 把判断留给 Skill、把鉴权与执行收敛到 CLI,经验才会从文档沉淀成稳定交付链路。 原文链接:AI小老六 导语 团队里经常会出现一种很尴尬的能力:大家都知道这件事怎么做,也有人能把它讲清楚,可它始终停留在"得找熟人问""得翻上次会话记录"这种状态。看上去经验很多,真正能稳定复用的却不多。 在 A
( 2
min )
调用`IChatClient`的`GetResponseAsync`或者`GetStreamingResponseAsync`方法时,我们通常会传入一个`ChatOptions`对象来控制运行行为。`ConfigureOptionsChatClient`利用指定的委托对象来动态设置`ChatOpti...
( 3
min )
把判断留给 Skill、把鉴权与执行收敛到 CLI,经验才会从文档沉淀成稳定交付链路。 原文链接:AI小老六 导语 团队里经常会出现一种很尴尬的能力:大家都知道这件事怎么做,也有人能把它讲清楚,可它始终停留在"得找熟人问""得翻上次会话记录"这种状态。看上去经验很多,真正能稳定复用的却不多。 在 A
( 2
min )
调用`IChatClient`的`GetResponseAsync`或者`GetStreamingResponseAsync`方法时,我们通常会传入一个`ChatOptions`对象来控制运行行为。`ConfigureOptionsChatClient`利用指定的委托对象来动态设置`ChatOpti...
( 3
min )
 I was having a strange error with my DJI Air3s drone, it was reporting that I wasn’t connected. Then after I try to connect typing my email (and confirming the agree checkbox) it was reporting “Check network” error. And it no matter which WiFi network or hotspot I use, it always was reporting this error. … Continue reading Fixing the DJI RC2 login error “Check network” →
( 11
min )
curl disclosed a bug submitted by byteray_ltd: https://hackerone.com/reports/3788506
curl disclosed a bug submitted by kalfkinen: https://hackerone.com/reports/3786077
I was having a strange error with my DJI Air3s drone, it was reporting that I wasn’t connected. Then after I try to connect typing my email (and confirming the agree checkbox) it was reporting “Check network” error. And it no matter which WiFi network or hotspot I use, it always was reporting this error. … Continue reading Fixing the DJI RC2 login error “Check network” →
( 11
min )
curl disclosed a bug submitted by byteray_ltd: https://hackerone.com/reports/3788506
curl disclosed a bug submitted by kalfkinen: https://hackerone.com/reports/3786077
 Ruby on Rails disclosed a bug submitted by ooooooo_q: https://hackerone.com/reports/2389431
curl disclosed a bug submitted by byteray_ltd: https://hackerone.com/reports/3788506
curl disclosed a bug submitted by kalfkinen: https://hackerone.com/reports/3786077
Ruby on Rails disclosed a bug submitted by ooooooo_q: https://hackerone.com/reports/2389431
升级到 EF Core 8 后,原本文能正常运行的 Contains 查询可能因生成 CTE 语法且缺少前置分号,而触发 SQL Server 错误(错误号 156)。这是 EF Core 8 有意引入的重大变更。为此,文章推荐使用参数化 Raw SQL、FindAsync 或内存过滤作为解决方案;...
( 4
min )
Ruby on Rails disclosed a bug submitted by ooooooo_q: https://hackerone.com/reports/2389431
curl disclosed a bug submitted by byteray_ltd: https://hackerone.com/reports/3788506
curl disclosed a bug submitted by kalfkinen: https://hackerone.com/reports/3786077
Ruby on Rails disclosed a bug submitted by ooooooo_q: https://hackerone.com/reports/2389431
升级到 EF Core 8 后,原本文能正常运行的 Contains 查询可能因生成 CTE 语法且缺少前置分号,而触发 SQL Server 错误(错误号 156)。这是 EF Core 8 有意引入的重大变更。为此,文章推荐使用参数化 Raw SQL、FindAsync 或内存过滤作为解决方案;...
( 4
min )
 Pwn 时间跳跃 先用ida看看 普通的菜单题,第一个这个比较的是字符的1234,所以输字符,输入2有栈溢出,打ret2libc即可。exp如下: #!/usr/bin/env python3 from pwn import * import sys from ctypes import * #fr
( 4
min )
Pwn 时间跳跃 先用ida看看 普通的菜单题,第一个这个比较的是字符的1234,所以输字符,输入2有栈溢出,打ret2libc即可。exp如下: #!/usr/bin/env python3 from pwn import * import sys from ctypes import * #fr
( 4
min )
 在AI与微服务深度融合的开发场景中,传统智能体组件普遍存在对接方式单一、工具扩展困难、微服务适配性差、知识体系零散等问题,难以适配企业级复杂研发流程。基于云驿插件平台构建的AI Agent组件(开发助手智能体 AgentForge),打造了一套轻量化、高兼容、可扩展的智能开发解决方案,既支持本地工具
( 1
min )
当Agent决定“改造环境”:记一次因弱模型作弊导致的实验数据全零事件 故事背景 最近有一篇论文在做实验,发现了一个很有趣的实验现象,那就是我的最弱的模型所在的对照组,其中最复杂的测试对象——PaddlePaddle库总是所有数据都是0。 这篇论文的一个核心任务是让大模型针对某一个被测Python库
( 1
min )
AI Prompt 工程化设计最佳实践 一份面向软件工程师的 Prompt 设计方法论,适用于任何需要系统化、工程化提升 LLM 输出质量的场景。 涵盖从简单问答到复杂的多阶段生成流水线的通用原则。 目录 核心理念:把 Prompt 当作代码 原则一:Plan-and-Prompt 分离 原则二:多
( 6
min )
在AI与微服务深度融合的开发场景中,传统智能体组件普遍存在对接方式单一、工具扩展困难、微服务适配性差、知识体系零散等问题,难以适配企业级复杂研发流程。基于云驿插件平台构建的AI Agent组件(开发助手智能体 AgentForge),打造了一套轻量化、高兼容、可扩展的智能开发解决方案,既支持本地工具
( 1
min )
当Agent决定“改造环境”:记一次因弱模型作弊导致的实验数据全零事件 故事背景 最近有一篇论文在做实验,发现了一个很有趣的实验现象,那就是我的最弱的模型所在的对照组,其中最复杂的测试对象——PaddlePaddle库总是所有数据都是0。 这篇论文的一个核心任务是让大模型针对某一个被测Python库
( 1
min )
AI Prompt 工程化设计最佳实践 一份面向软件工程师的 Prompt 设计方法论,适用于任何需要系统化、工程化提升 LLM 输出质量的场景。 涵盖从简单问答到复杂的多阶段生成流水线的通用原则。 目录 核心理念:把 Prompt 当作代码 原则一:Plan-and-Prompt 分离 原则二:多
( 6
min )
 AI Coding 压缩了写码环节,却把瓶颈转移到 边界澄清、质量把关、跨角色协同 和 上线决策。 原文链接:AI 小老六 很多团队最近都有同一种错觉:代码明显写得更快了,需求却没有同样幅度地更早上线。人没有更闲,反而更容易被多个需求、多个 Agent、多个评审点位同时拉扯。 这不是工具失灵
( 2
min )
AI Coding 压缩了写码环节,却把瓶颈转移到 边界澄清、质量把关、跨角色协同 和 上线决策。 原文链接:AI 小老六 很多团队最近都有同一种错觉:代码明显写得更快了,需求却没有同样幅度地更早上线。人没有更闲,反而更容易被多个需求、多个 Agent、多个评审点位同时拉扯。 这不是工具失灵
( 2
min )
 Cloud Agent 开发笔记(4):Skill 与 MCP 集成、项目后记 上一篇讲了 Agent 事件如何推到浏览器、数据如何持久化、多会话和中断如何处理。这一篇讲能力扩展层:Skill 系统和 MCP 集成。 V1 验证的是产品形态:由管理员角色集中创建和维护 Skill、配置 MCP 连接
( 4
min )
老铁们,你还在搭建复杂的自动化测试框架? 还在手写大量定位、断言、报告? 还在让团队被重复回归测试拖垮效率? 别急,今天给大家带来 browser-use 官方出品的终极测试平台 —— QA Use,一款真正面向测试团队、开箱即用的 AI 驱动 E2E 测试系统。不用写代码、不用搭环境、不用维护脚本
( 3
min )
curl disclosed a bug submitted by torkd1: https://hackerone.com/reports/3785919
curl disclosed a bug submitted by maxhearnden: https://hackerone.com/reports/3780733
curl disclosed a bug submitted by torkd1: https://hackerone.com/reports/3785919
curl disclosed a bug submitted by maxhearnden: https://hackerone.com/reports/3780733
Cloud Agent 开发笔记(4):Skill 与 MCP 集成、项目后记 上一篇讲了 Agent 事件如何推到浏览器、数据如何持久化、多会话和中断如何处理。这一篇讲能力扩展层:Skill 系统和 MCP 集成。 V1 验证的是产品形态:由管理员角色集中创建和维护 Skill、配置 MCP 连接
( 4
min )
老铁们,你还在搭建复杂的自动化测试框架? 还在手写大量定位、断言、报告? 还在让团队被重复回归测试拖垮效率? 别急,今天给大家带来 browser-use 官方出品的终极测试平台 —— QA Use,一款真正面向测试团队、开箱即用的 AI 驱动 E2E 测试系统。不用写代码、不用搭环境、不用维护脚本
( 3
min )
curl disclosed a bug submitted by torkd1: https://hackerone.com/reports/3785919
curl disclosed a bug submitted by maxhearnden: https://hackerone.com/reports/3780733
curl disclosed a bug submitted by torkd1: https://hackerone.com/reports/3785919
curl disclosed a bug submitted by maxhearnden: https://hackerone.com/reports/3780733
 本文介绍一种让大语言模型制作幻灯片的实验性思路。通过定义一套极简的 XML 标签语言 SlideML,让模型输出页面描述,再由确定性渲染引擎真实绘制,并利用测量到的实际数据回传给模型,形成一轮一轮的调整优化。
( 8
min )
绝大部分的Agent都采用对话的方式来和用户进行交互,所以对话的内容就成了Agent决策的基础,对话历史也成为占据LLM上下文窗口的主要内容。LLM推理的质量并非与上下文的丰富程度成正向关系,有时候过多的上下文信息反而会干扰Agent的判断,导致它做出错误的决策。`ReducingChatClien...
( 3
min )
本文介绍一种让大语言模型制作幻灯片的实验性思路。通过定义一套极简的 XML 标签语言 SlideML,让模型输出页面描述,再由确定性渲染引擎真实绘制,并利用测量到的实际数据回传给模型,形成一轮一轮的调整优化。
( 8
min )
绝大部分的Agent都采用对话的方式来和用户进行交互,所以对话的内容就成了Agent决策的基础,对话历史也成为占据LLM上下文窗口的主要内容。LLM推理的质量并非与上下文的丰富程度成正向关系,有时候过多的上下文信息反而会干扰Agent的判断,导致它做出错误的决策。`ReducingChatClien...
( 3
min )
 在PyTorch中,数据集(Data Set)和数据加载器(Data Loader)是实现深度学习模型和测试的基本组件。下面将首先介绍数据集(Data Set)和数据加载器(Data Loader)的概念,然后介绍如何创建和使用PyTorch中的数据加载器的一些步骤和示例。
( 3
min )
身份验证是每个后端项目的“第一道门”,但往往也是劝退新手的第一大坑。本文不讲虚的,以一个全栈工程师的真实踩坑视角,带你梳理 FastAPI 身份验证与用户管理的最优解—— FastAPI Users 库,从安装、实战到选型建议,一条龙拆解。如果你正被 JWT、Cookie、数据库迁移搞得头秃,这篇“...
( 2
min )
编译 1. 测试能否进入 PostgreSQL 先执行: sudo -u postgres psql -c "SELECT version();" 如果能输出 PostgreSQL 版本,说明数据库服务正常。 2. 创建 TPC-H 测试数据库 你当前 Linux 用户是 username,先检查
( 8
min )
在PyTorch中,数据集(Data Set)和数据加载器(Data Loader)是实现深度学习模型和测试的基本组件。下面将首先介绍数据集(Data Set)和数据加载器(Data Loader)的概念,然后介绍如何创建和使用PyTorch中的数据加载器的一些步骤和示例。
( 3
min )
身份验证是每个后端项目的“第一道门”,但往往也是劝退新手的第一大坑。本文不讲虚的,以一个全栈工程师的真实踩坑视角,带你梳理 FastAPI 身份验证与用户管理的最优解—— FastAPI Users 库,从安装、实战到选型建议,一条龙拆解。如果你正被 JWT、Cookie、数据库迁移搞得头秃,这篇“...
( 2
min )
编译 1. 测试能否进入 PostgreSQL 先执行: sudo -u postgres psql -c "SELECT version();" 如果能输出 PostgreSQL 版本,说明数据库服务正常。 2. 创建 TPC-H 测试数据库 你当前 Linux 用户是 username,先检查
( 8
min )
 在线体验:geekformat.com/zh-CN/pdf/edit(不用注册、不上传文件,浏览器里就能玩) 故事开头 老板:这份 50 页的合同 PDF,你帮我在每页右下角加个页码,再把所有"乙方"的位置画个箭头。 你:好的(熟练打开 Adobe Acrobat 准备买会员)。 老板:用免费
( 10
min )
前言 在用 deepagents 做 Chatbot 的时候,有个最基本的需求:Agent 得记住上一轮聊了什么。你不能每轮对话都让用户重新自我介绍一遍。 LangGraph / DeepAgents 内置了一个叫 checkpoint 的机制来处理这个事。开发阶段用 MemorySaver 跑跑
( 3
min )
博客地址:https://www.cnblogs.com/zylyehuo/ 一、问题描述 在 Ubuntu 20.04 系统中连接 HC-05 蓝牙串口模块时,Windows 系统可以正常连接,但 Ubuntu 系统中会出现蓝牙可以搜索到、PIN 码输入正确、设备可以配对成功,但是连接后立即断开的
( 5
min )
在线体验:geekformat.com/zh-CN/pdf/edit(不用注册、不上传文件,浏览器里就能玩) 故事开头 老板:这份 50 页的合同 PDF,你帮我在每页右下角加个页码,再把所有"乙方"的位置画个箭头。 你:好的(熟练打开 Adobe Acrobat 准备买会员)。 老板:用免费
( 10
min )
前言 在用 deepagents 做 Chatbot 的时候,有个最基本的需求:Agent 得记住上一轮聊了什么。你不能每轮对话都让用户重新自我介绍一遍。 LangGraph / DeepAgents 内置了一个叫 checkpoint 的机制来处理这个事。开发阶段用 MemorySaver 跑跑
( 3
min )
博客地址:https://www.cnblogs.com/zylyehuo/ 一、问题描述 在 Ubuntu 20.04 系统中连接 HC-05 蓝牙串口模块时,Windows 系统可以正常连接,但 Ubuntu 系统中会出现蓝牙可以搜索到、PIN 码输入正确、设备可以配对成功,但是连接后立即断开的
( 5
min )
 目录环境配置安装 HailoRT安装 Hailo-OllamaPython 环境启动 Hailo-Ollama 服务实现 RAG 应用1. 引用相关包2. PDF 文档处理3. 文本切分4. 向量化和存储5. 自定义 HailoChatOllama 类6. RAG 链的组装LoRA 微调1. 微调2
( 5
min )
目录环境配置安装 HailoRT安装 Hailo-OllamaPython 环境启动 Hailo-Ollama 服务实现 RAG 应用1. 引用相关包2. PDF 文档处理3. 文本切分4. 向量化和存储5. 自定义 HailoChatOllama 类6. RAG 链的组装LoRA 微调1. 微调2
( 5
min )
 一、Managed Agents 原理 1.1、诞生背景:从 “单体” 走向 “全托管” 随着大模型工具调用与自主决策能力持续升级,AI Agent 已逐渐深入研发各落地场景。 但单体 Agent 普遍存在「架构耦合、运维成本高、无法团队协作、能力沉淀复用难」等痛点,分析原因为: 多数单体 Agen
( 3
min )
一、Managed Agents 原理 1.1、诞生背景:从 “单体” 走向 “全托管” 随着大模型工具调用与自主决策能力持续升级,AI Agent 已逐渐深入研发各落地场景。 但单体 Agent 普遍存在「架构耦合、运维成本高、无法团队协作、能力沉淀复用难」等痛点,分析原因为: 多数单体 Agen
( 3
min )
 从GPT-1的诞生到ChatGPT的横空出世,AI从专家的实验室走进了每个人的日常,这背后是数据、算力与算法长达七十年的厚积薄发。
( 1
min )
从GPT-1的诞生到ChatGPT的横空出世,AI从专家的实验室走进了每个人的日常,这背后是数据、算力与算法长达七十年的厚积薄发。
( 1
min )
 Really cool instructions and 3D parts provided:
( 11
min )
curl disclosed a bug submitted by awofjawofjfawf: https://hackerone.com/reports/3781305
curl disclosed a bug submitted by fanhua: https://hackerone.com/reports/3749428
curl disclosed a bug submitted by alphalaab: https://hackerone.com/reports/3766392
curl disclosed a bug submitted by awofjawofjfawf: https://hackerone.com/reports/3781305
curl disclosed a bug submitted by fanhua: https://hackerone.com/reports/3749428
curl disclosed a bug submitted by alphalaab: https://hackerone.com/reports/3766392
Really cool instructions and 3D parts provided:
( 11
min )
curl disclosed a bug submitted by awofjawofjfawf: https://hackerone.com/reports/3781305
curl disclosed a bug submitted by fanhua: https://hackerone.com/reports/3749428
curl disclosed a bug submitted by alphalaab: https://hackerone.com/reports/3766392
curl disclosed a bug submitted by awofjawofjfawf: https://hackerone.com/reports/3781305
curl disclosed a bug submitted by fanhua: https://hackerone.com/reports/3749428
curl disclosed a bug submitted by alphalaab: https://hackerone.com/reports/3766392
 第一篇:PowerMem 记忆系统的遗忘设计,从神经元到代码工程 上一篇 PowerMem 记忆系统的遗忘设计,从神经元到代码工程 从认知科学的角度聊了遗忘机制,包括突触可塑性、艾宾浩斯遗忘曲线、间隔重复和理想的困难。都是一些很有意思的认知学理论。 这一篇换个视角,以一条消息的流转路径为线索,跟踪它
( 5
min )
第一篇:PowerMem 记忆系统的遗忘设计,从神经元到代码工程 上一篇 PowerMem 记忆系统的遗忘设计,从神经元到代码工程 从认知科学的角度聊了遗忘机制,包括突触可塑性、艾宾浩斯遗忘曲线、间隔重复和理想的困难。都是一些很有意思的认知学理论。 这一篇换个视角,以一条消息的流转路径为线索,跟踪它
( 5
min )
 铁王座从不是永恒的。当OpenAI与Anthropic疯狂封锁+86、猎杀中文开发者时,它们不知道——真正的“凛冬”,正由那些被它们亲手推开的弑君者带来。 凛冬已至,疯王犹在炉边添野火 《权力的游戏》里,史塔克家族世代传诵一句警言:“Winter is Coming.” 凛冬降临时,长城之外的白鬼会
( 1
min )
一、从一次"差口气"说起 老陈做了五年前端,最近接了个全栈私活:Python 后端加 React 前端,登录、注册、JWT、邮箱验证,外加一个管理后台。 听起来不大。干起来才发现处处别扭。 本地跑得挺顺的代码,一推到线上就报错。pip install 装出来的版本和 lock 文件对不上,celer
( 23
min )
铁王座从不是永恒的。当OpenAI与Anthropic疯狂封锁+86、猎杀中文开发者时,它们不知道——真正的“凛冬”,正由那些被它们亲手推开的弑君者带来。 凛冬已至,疯王犹在炉边添野火 《权力的游戏》里,史塔克家族世代传诵一句警言:“Winter is Coming.” 凛冬降临时,长城之外的白鬼会
( 1
min )
一、从一次"差口气"说起 老陈做了五年前端,最近接了个全栈私活:Python 后端加 React 前端,登录、注册、JWT、邮箱验证,外加一个管理后台。 听起来不大。干起来才发现处处别扭。 本地跑得挺顺的代码,一推到线上就报错。pip install 装出来的版本和 lock 文件对不上,celer
( 23
min )
 一、为什么要单独理解 Slash Command 用 Agent 做事时,经常会遇到以 / 开头的输入: /help /new /model /skill markdown-to-wechat-richtext 这类输入就是 Slash Command。 它看起来像一句聊天消息,但本质上更接近“命令
( 5
min )
2022年,索尼AI车手GT Sophy在《GT赛车》里,用比人类冠军快2秒的圈速证明:AI已经能在公平竞争中“征服”赛道。就像围棋国手古力9岁时赢了父亲古巨山,从此父亲的角色从“对手”变成“陪练”——未来的AI,或许就是那个永远比人类强的“棋王父亲”。而这个“超越时刻”,可能比我们想象的更近。 一
( 1
min )
谨以此篇Blog记录我的大学四年生活. 我们这一届学生是刚好大一的时候ChatGPT开始出名, 然后AI快速发展, 到现在快毕业了, Claude都厉害成这个样子了 一个南方四非计算机学生的记录, 较多踩坑, 少量信息差. 即使是这样卷也没有看到所谓的光明未来, 研究生完全不一定是我需要的, 只是本
( 2
min )
一、为什么要单独理解 Slash Command 用 Agent 做事时,经常会遇到以 / 开头的输入: /help /new /model /skill markdown-to-wechat-richtext 这类输入就是 Slash Command。 它看起来像一句聊天消息,但本质上更接近“命令
( 5
min )
2022年,索尼AI车手GT Sophy在《GT赛车》里,用比人类冠军快2秒的圈速证明:AI已经能在公平竞争中“征服”赛道。就像围棋国手古力9岁时赢了父亲古巨山,从此父亲的角色从“对手”变成“陪练”——未来的AI,或许就是那个永远比人类强的“棋王父亲”。而这个“超越时刻”,可能比我们想象的更近。 一
( 1
min )
谨以此篇Blog记录我的大学四年生活. 我们这一届学生是刚好大一的时候ChatGPT开始出名, 然后AI快速发展, 到现在快毕业了, Claude都厉害成这个样子了 一个南方四非计算机学生的记录, 较多踩坑, 少量信息差. 即使是这样卷也没有看到所谓的光明未来, 研究生完全不一定是我需要的, 只是本
( 2
min )
 superpower 是开源社区非常出名的 harness 框架, 我们在本文通过数栈产品 easyIndex 的复杂需求实现来探究 superpower 的价值。
( 2
min )
P15799 [GESP202603 五级] 找数 题目传送门:https://www.luogu.com.cn/problem/P15799 题目背景 对应的选择、判断题:https://ti.luogu.com.cn/problemset/1209 题目描述 给定一个包含 n 个互不相同的正整数
( 2
min )
superpower 是开源社区非常出名的 harness 框架, 我们在本文通过数栈产品 easyIndex 的复杂需求实现来探究 superpower 的价值。
( 2
min )
P15799 [GESP202603 五级] 找数 题目传送门:https://www.luogu.com.cn/problem/P15799 题目背景 对应的选择、判断题:https://ti.luogu.com.cn/problemset/1209 题目描述 给定一个包含 n 个互不相同的正整数
( 2
min )
 2016年,AlphaGo的胜利让AI成为全民话题,但这并非凭空降临,而是机器学习、图像识别、自然语言处理等多项基础技术二十年来不断积累与融合的结果。
( 1
min )
2026 年 6 月,Linux 基金会旗下的[智能体 AI 基金会(AAIF)正式接纳 AgentGateway 为第四大核心托管项目](https://aaif.io/blog/agentgateway-joins-aaif-as-an-open-gateway-for-agentic-ai-i
( 2
min )
背景 考虑这样一个问题: 给定 \(n, r, p\) ,求 \[\binom{n}{r} \bmod m \]不保证 \(m\) 是质数。\(1\le r\le n\le 10^{18}\)。 显然此时普通 Lucas 定理就无能为力了。这时需要用到扩展 Lucas 定理(exLucas)。 前置
( 5
min )
2016年,AlphaGo的胜利让AI成为全民话题,但这并非凭空降临,而是机器学习、图像识别、自然语言处理等多项基础技术二十年来不断积累与融合的结果。
( 1
min )
2026 年 6 月,Linux 基金会旗下的[智能体 AI 基金会(AAIF)正式接纳 AgentGateway 为第四大核心托管项目](https://aaif.io/blog/agentgateway-joins-aaif-as-an-open-gateway-for-agentic-ai-i
( 2
min )
背景 考虑这样一个问题: 给定 \(n, r, p\) ,求 \[\binom{n}{r} \bmod m \]不保证 \(m\) 是质数。\(1\le r\le n\le 10^{18}\)。 显然此时普通 Lucas 定理就无能为力了。这时需要用到扩展 Lucas 定理(exLucas)。 前置
( 5
min )
 多Agent开发笔记:为什么4个Codex加1个Claude会把9700X跑满 好家伙, vscode里开了四个codex拓展 + 一个 claude把我cpu吃满了,不是哥们,我9700X啊 按理说,8 核 16 线程的桌面 CPU,日常开发应该不算弱. 但我同时开了: 4 个 Codex 1 个
( 4
min )
tldr: 1、好 prompt 是激活正确分布:底层原理 2、对于强 agentic 模型,过度规则会造成模型开始“执行规则”,而不是进入状态:不同模型,不同策略 3、编写prompt的采样也是在挖掘自己的真正需求:模型可以走多远、现在这个路径是不是正确的? 4、模型采样输出prompt和对应回答
( 3
min )
多Agent开发笔记:为什么4个Codex加1个Claude会把9700X跑满 好家伙, vscode里开了四个codex拓展 + 一个 claude把我cpu吃满了,不是哥们,我9700X啊 按理说,8 核 16 线程的桌面 CPU,日常开发应该不算弱. 但我同时开了: 4 个 Codex 1 个
( 4
min )
tldr: 1、好 prompt 是激活正确分布:底层原理 2、对于强 agentic 模型,过度规则会造成模型开始“执行规则”,而不是进入状态:不同模型,不同策略 3、编写prompt的采样也是在挖掘自己的真正需求:模型可以走多远、现在这个路径是不是正确的? 4、模型采样输出prompt和对应回答
( 3
min )
 声明:本文在写作过程中使用了AI辅助工具进行资料整理、结构优化与语言润色。核心观点、技术判断与工程经验均为作者原创。 一、问题:卡在渲染层 项目里有这样一条链路:用 LLM 按指定的 schema 抽取领域数据(structured output),拿到结构化数据后,前端写代码把它渲染出来: typ
( 3
min )
声明:本文在写作过程中使用了AI辅助工具进行资料整理、结构优化与语言润色。核心观点、技术判断与工程经验均为作者原创。 一、问题:卡在渲染层 项目里有这样一条链路:用 LLM 按指定的 schema 抽取领域数据(structured output),拿到结构化数据后,前端写代码把它渲染出来: typ
( 3
min )
 AiInsight 问数框架将大模型、技能包、数据源、工艺知识库和工具执行统一到一个智能体流程中。用户可以用自然语言或明确命令发起任务,系统根据已选大模型、技能、数据源、文件和知识库构造上下文,分步骤完成数据查询、工艺推理、脚本分析和报告生成等过程。
( 2
min )
AiInsight 问数框架将大模型、技能包、数据源、工艺知识库和工具执行统一到一个智能体流程中。用户可以用自然语言或明确命令发起任务,系统根据已选大模型、技能、数据源、文件和知识库构造上下文,分步骤完成数据查询、工艺推理、脚本分析和报告生成等过程。
( 2
min )
 做测试的同学都知道,用例评审是个"苦力活"。 每次需求变更,都要手动对比:现有用例覆盖了哪些功能点?需求里的功能是否还有遗漏?边界条件考虑了吗?异常场景测了吗? 拿着Excel用例,对着几十页的PRD文档,一条一条核对,眼睛看花了不说,还容易漏。更要命的是——评审结果全靠人工判断,不同人评审标准还不
( 1
min )
做测试的同学都知道,用例评审是个"苦力活"。 每次需求变更,都要手动对比:现有用例覆盖了哪些功能点?需求里的功能是否还有遗漏?边界条件考虑了吗?异常场景测了吗? 拿着Excel用例,对着几十页的PRD文档,一条一条核对,眼睛看花了不说,还容易漏。更要命的是——评审结果全靠人工判断,不同人评审标准还不
( 1
min )
 自建 Copilot Cli 代理:让 GitHub Copilot 真正"Bring Your Own Key" Github: https://github.com/wosledon/copilot-auto-byok 一个基于 .NET 10 的轻量级模型代理,解决 Copilot Cli 只
( 2
min )
自建 Copilot Cli 代理:让 GitHub Copilot 真正"Bring Your Own Key" Github: https://github.com/wosledon/copilot-auto-byok 一个基于 .NET 10 的轻量级模型代理,解决 Copilot Cli 只
( 2
min )
 在 AI 训练、数据集管理等大规模文件访问场景中,随着文件数量和访问并发增加,元数据层往往更早成为性能瓶颈。无论是删除百万级小文件、克隆大规模数据集,还是高并发目录遍历,元数据引擎的响应能力都会直接影响上层业务效率。 JuiceFS 社区版 1.4 在元数据引擎层面引入了三项优化:批量删除(Batc
( 2
min )
在 AI 训练、数据集管理等大规模文件访问场景中,随着文件数量和访问并发增加,元数据层往往更早成为性能瓶颈。无论是删除百万级小文件、克隆大规模数据集,还是高并发目录遍历,元数据引擎的响应能力都会直接影响上层业务效率。 JuiceFS 社区版 1.4 在元数据引擎层面引入了三项优化:批量删除(Batc
( 2
min )
 从口袋里的手机屏幕,到工厂里不知疲倦的生产线;从农田里监测土壤的探头,到管道中识别介质的开关,电容传感器早已成为现代社会中 “看不见的感知触手”。它无需物理接触,却能感知万物的细微变化,以多样的形态适配着消费电子、工业控制、农业监测等无数场景,渗透到我们生活与生产的每一个角落。
( 4
min )
你是不是也有台旧安卓在抽屉里吃灰?其实只要装上Termux,再跑个FileBrowser,十分钟就能变成一台7×24小时在线的私人云盘,再也不用忍受网盘限速和和谐。这篇文章不仅手把手带你实战搭建,还会横向对比几种常见方案,把我踩过的坑、最稳的配置一次讲清楚,让你少走冤枉路。
( 2
min )
我有一点隐隐的不安:AI时代,知识会不会被少数人“圈养”起来? 引言 在这个大模型发展日新月异的时代,国内外的模型层出不穷——国外有GPT、Claude、Gemini,国内有GLM、Qwen、Minimax等等。它们帮我们处理很多事情,让我们能更高效地应对生活。 但大模型越来越强大,人们也越来越依赖
( 2
min )
说实话,我第一次看到 Claude Code v2.1.139 的 changelog,以为只是个普通版本更新——新功能扫了一眼,Agent 视图和 /goal 命令,感觉不就是「任务管理器」和「批量执行」嘛,有什么大惊小怪的。 结果真正用了两天,才发现自己浅了。 这次更新不是在 Claude Co
( 3
min )
从口袋里的手机屏幕,到工厂里不知疲倦的生产线;从农田里监测土壤的探头,到管道中识别介质的开关,电容传感器早已成为现代社会中 “看不见的感知触手”。它无需物理接触,却能感知万物的细微变化,以多样的形态适配着消费电子、工业控制、农业监测等无数场景,渗透到我们生活与生产的每一个角落。
( 4
min )
你是不是也有台旧安卓在抽屉里吃灰?其实只要装上Termux,再跑个FileBrowser,十分钟就能变成一台7×24小时在线的私人云盘,再也不用忍受网盘限速和和谐。这篇文章不仅手把手带你实战搭建,还会横向对比几种常见方案,把我踩过的坑、最稳的配置一次讲清楚,让你少走冤枉路。
( 2
min )
我有一点隐隐的不安:AI时代,知识会不会被少数人“圈养”起来? 引言 在这个大模型发展日新月异的时代,国内外的模型层出不穷——国外有GPT、Claude、Gemini,国内有GLM、Qwen、Minimax等等。它们帮我们处理很多事情,让我们能更高效地应对生活。 但大模型越来越强大,人们也越来越依赖
( 2
min )
说实话,我第一次看到 Claude Code v2.1.139 的 changelog,以为只是个普通版本更新——新功能扫了一眼,Agent 视图和 /goal 命令,感觉不就是「任务管理器」和「批量执行」嘛,有什么大惊小怪的。 结果真正用了两天,才发现自己浅了。 这次更新不是在 Claude Co
( 3
min )
 把低频 Skill 变成可检索冷存储,让 Agent 按需找回能力,省上下文也更稳。 原文链接:AI小老六 导语 Agent 的能力越来越像一个小型操作系统:它能读文件、调接口、写代码、查日历,也能按团队经验执行一套固定流程。Skill 就是把这些经验沉淀下来的常见方式。 问题也随之出现。Skill
( 3
min )
把低频 Skill 变成可检索冷存储,让 Agent 按需找回能力,省上下文也更稳。 原文链接:AI小老六 导语 Agent 的能力越来越像一个小型操作系统:它能读文件、调接口、写代码、查日历,也能按团队经验执行一套固定流程。Skill 就是把这些经验沉淀下来的常见方式。 问题也随之出现。Skill
( 3
min )
 MySQL-Seconds_behind_master的精度误差 前言 Seconds_behind_master是我们观察主从延迟的一个重要指标。但任何指标所能表示的精度都是有限的。例如用精度只能到秒的指标去衡量毫秒级的表现就会产生非常大的误差。如果再以此误差去分析问题,就会让思维走上弯路。例如用
( 2
min )
我们知道LLM的调用不仅仅是一个耗时的操作,还会产生一定的费用,所以我们希望能够尽可能地减少不必要的调用。`CachingChatClient`就是为此而生的一个中间件实现,它通过在内存中维护一个缓存来存储之前调用LLM的输入和输出,从而避免了对相同输入的重复调用。当我们调用`GetResponse...
( 3
min )
MySQL-Seconds_behind_master的精度误差 前言 Seconds_behind_master是我们观察主从延迟的一个重要指标。但任何指标所能表示的精度都是有限的。例如用精度只能到秒的指标去衡量毫秒级的表现就会产生非常大的误差。如果再以此误差去分析问题,就会让思维走上弯路。例如用
( 2
min )
我们知道LLM的调用不仅仅是一个耗时的操作,还会产生一定的费用,所以我们希望能够尽可能地减少不必要的调用。`CachingChatClient`就是为此而生的一个中间件实现,它通过在内存中维护一个缓存来存储之前调用LLM的输入和输出,从而避免了对相同输入的重复调用。当我们调用`GetResponse...
( 3
min )
 从AlphaGo的棋局到日常的对话与绘画,我们正享受着AI带来的便利,但你是否想过,这位无所不能的‘大脑’,是如何从七十年前那个夏天的纸上谈兵,一步步成长起来的?
( 1
min )
curl disclosed a bug submitted by argus-systems: https://hackerone.com/reports/3784125
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3717552
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3718265
curl disclosed a bug submitted by hamaowo: https://hackerone.com/reports/3776535
curl disclosed a bug submitted by bowen111: https://hackerone.com/reports/3776433
curl disclosed a bug submitted by skksndk: https://hackerone.com/reports/3774977
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3766065
curl disclosed a bug submitted by argus-systems: https://hackerone.com/reports/3784125
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3717552
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3718265
curl disclosed a bug submitted by hamaowo: https://hackerone.com/reports/3776535
curl disclosed a bug submitted by bowen111: https://hackerone.com/reports/3776433
curl disclosed a bug submitted by skksndk: https://hackerone.com/reports/3774977
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3766065
[Begin]AI Learn Data Day 0 最近一直在学 AI 全栈开发。关于全栈,略懂一二;关于 AI,则完全是个新手。 说到底我还没学完全栈,后端的内容比如 Redis 根本没学,只知道是个什么东西,教学视频太长看不下去。然后转到 AI 这边,或许因为是新方向的缘故,网上连一篇成体系的
( 3
min )
从AlphaGo的棋局到日常的对话与绘画,我们正享受着AI带来的便利,但你是否想过,这位无所不能的‘大脑’,是如何从七十年前那个夏天的纸上谈兵,一步步成长起来的?
( 1
min )
curl disclosed a bug submitted by argus-systems: https://hackerone.com/reports/3784125
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3717552
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3718265
curl disclosed a bug submitted by hamaowo: https://hackerone.com/reports/3776535
curl disclosed a bug submitted by bowen111: https://hackerone.com/reports/3776433
curl disclosed a bug submitted by skksndk: https://hackerone.com/reports/3774977
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3766065
curl disclosed a bug submitted by argus-systems: https://hackerone.com/reports/3784125
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3717552
curl disclosed a bug submitted by bagder: https://hackerone.com/reports/3718265
curl disclosed a bug submitted by hamaowo: https://hackerone.com/reports/3776535
curl disclosed a bug submitted by bowen111: https://hackerone.com/reports/3776433
curl disclosed a bug submitted by skksndk: https://hackerone.com/reports/3774977
curl disclosed a bug submitted by azraelxuemo: https://hackerone.com/reports/3766065
[Begin]AI Learn Data Day 0 最近一直在学 AI 全栈开发。关于全栈,略懂一二;关于 AI,则完全是个新手。 说到底我还没学完全栈,后端的内容比如 Redis 根本没学,只知道是个什么东西,教学视频太长看不下去。然后转到 AI 这边,或许因为是新方向的缘故,网上连一篇成体系的
( 3
min )
 上一篇我们看了现代大模型对归一化的改造。 RMSNorm 去掉了均值中心化,只保留均方根缩放:一个沿用多年的标准组件,拆开一看,其中一部分工作在现代整体架构中已经有些多余了。 本篇来看第二个改动:Transformer 架构中的 FFN (MLP) 层的重构,而其具体内容,需要先从激活函数说起。 1
( 3
min )
上一篇我们看了现代大模型对归一化的改造。 RMSNorm 去掉了均值中心化,只保留均方根缩放:一个沿用多年的标准组件,拆开一看,其中一部分工作在现代整体架构中已经有些多余了。 本篇来看第二个改动:Transformer 架构中的 FFN (MLP) 层的重构,而其具体内容,需要先从激活函数说起。 1
( 3
min )
 Means:基于 .NET 10 打造的开源自部署 S3 兼容对象存储服务 GitHub 地址:https://github.com/AIDotNet/Means 欢迎 Star ⭐、Fork、提 Issue 和 PR!MIT 开源协议,放心使用。 引言 对象存储已经成为现代云原生架构的基石。
( 3
min )
我们团队提出了 LiveMoments,这是首个专门针对 Live Photo 重选封面帧画质修复的解决方案,已被 ICLR 2026 录用。
针对用户重选封面时面临的画质降级痛点,我们利用 Live Photo 自带的原始高清封面作为参考,构建了一个包含运动对齐模块的参考引导扩散模型。
该方法有效...
( 2
min )
Means:基于 .NET 10 打造的开源自部署 S3 兼容对象存储服务 GitHub 地址:https://github.com/AIDotNet/Means 欢迎 Star ⭐、Fork、提 Issue 和 PR!MIT 开源协议,放心使用。 引言 对象存储已经成为现代云原生架构的基石。
( 3
min )
我们团队提出了 LiveMoments,这是首个专门针对 Live Photo 重选封面帧画质修复的解决方案,已被 ICLR 2026 录用。
针对用户重选封面时面临的画质降级痛点,我们利用 Live Photo 自带的原始高清封面作为参考,构建了一个包含运动对齐模块的参考引导扩散模型。
该方法有效...
( 2
min )
 按照新版计费规则,Copilot Pro+订阅用户 6.1~6.2 短短两天,7000 内置 Credits 全额耗尽、10 美元附加预算全部透支,折算实际产生计费成本超 49 美元。海外开发者同样发文吐槽,3 天掏空月度全部代币。
( 1
min )
三个月前,我第一次看到 superpowers 的时候,立刻觉得这东西有点厉害——14 个 skill 装进去,Claude Code 直接变成一套完整的软件工程流水线,TDD、代码审查、brainstorming 全覆盖。 GitHub 上已经 187K star 了,Medium 上的测评文章写
( 3
min )
按照新版计费规则,Copilot Pro+订阅用户 6.1~6.2 短短两天,7000 内置 Credits 全额耗尽、10 美元附加预算全部透支,折算实际产生计费成本超 49 美元。海外开发者同样发文吐槽,3 天掏空月度全部代币。
( 1
min )
三个月前,我第一次看到 superpowers 的时候,立刻觉得这东西有点厉害——14 个 skill 装进去,Claude Code 直接变成一套完整的软件工程流水线,TDD、代码审查、brainstorming 全覆盖。 GitHub 上已经 187K star 了,Medium 上的测评文章写
( 3
min )
 前言 本文主要描述Plan-and-Execute开发中的ReAct模式,并且使用一个demo,彻底搞懂怎么在实际工作中使用Plan-and-Execute模式 话不多说,我们开始 代码结构 代码地址 . ├── main.py # 主入口,串起规划、执行、分析三个阶段 ├── planner.py
( 2
min )
还在为FastAPI打包后各种报错抓狂?本文不讲虚的,用最接地气的方式对比Linux和Windows下三种主流打包部署方式,从PyInstaller的各种坑到Docker的一键起飞,手把手教你如何根据场景选择,附上保姆级实操命令,让你的服务“稳如老狗”。
( 2
min )
前言 本文主要描述Plan-and-Execute开发中的ReAct模式,并且使用一个demo,彻底搞懂怎么在实际工作中使用Plan-and-Execute模式 话不多说,我们开始 代码结构 代码地址 . ├── main.py # 主入口,串起规划、执行、分析三个阶段 ├── planner.py
( 2
min )
还在为FastAPI打包后各种报错抓狂?本文不讲虚的,用最接地气的方式对比Linux和Windows下三种主流打包部署方式,从PyInstaller的各种坑到Docker的一键起飞,手把手教你如何根据场景选择,附上保姆级实操命令,让你的服务“稳如老狗”。
( 2
min )
 用代码图谱重构 Agent 检索链路,让大仓库定位、调用链和影响面分析更稳更省。 原文链接:AI小老六 导语 代码 Agent 真正卡住的地方,往往不是模型不会写代码,而是它不知道该先看哪里。 面对一个陌生仓库,Agent 通常会先列目录,再搜关键词,接着打开几个文件,猜一个入口点,发现不对后再重复
( 3
min )
在众多预定义的`IChatClient`中间件中,`FunctionInvokingChatClient`无疑是最重要的一个,以至于没有它整个Agent就无法工作了。原因在于驱动Agent执行的核心机制的ReAct循环就是通过`FunctionInvokingChatClient`实现的,我们注册的...
( 3
min )
用代码图谱重构 Agent 检索链路,让大仓库定位、调用链和影响面分析更稳更省。 原文链接:AI小老六 导语 代码 Agent 真正卡住的地方,往往不是模型不会写代码,而是它不知道该先看哪里。 面对一个陌生仓库,Agent 通常会先列目录,再搜关键词,接着打开几个文件,猜一个入口点,发现不对后再重复
( 3
min )
在众多预定义的`IChatClient`中间件中,`FunctionInvokingChatClient`无疑是最重要的一个,以至于没有它整个Agent就无法工作了。原因在于驱动Agent执行的核心机制的ReAct循环就是通过`FunctionInvokingChatClient`实现的,我们注册的...
( 3
min )
 2022年年底,ChatGPT横空出世,两个月月活破亿,成为人类有史以来增长最快的互联网产品。 一夜之间,全世界都在讨论AI,都想着和ChatGPT对话。 ChatGPT是一夜爆火,但并不是凭空冒出来的。 上篇文章《AI不是从天而降,它经历了七十年三起三落:读懂AI的第三课》,我们知道从1950年图
( 1
min )
本文将深入浅出地讲解 JWT(JSON Web Token)在 .NET 8 中的应用。从原理到代码实战,手把手教你搭建用户登录接口颁发 Token,并配置 API 网关验证 Token,最终实现基于角色的接口权限控制,保护你的 API 不被非法访问。
( 3
min )
2022年年底,ChatGPT横空出世,两个月月活破亿,成为人类有史以来增长最快的互联网产品。 一夜之间,全世界都在讨论AI,都想着和ChatGPT对话。 ChatGPT是一夜爆火,但并不是凭空冒出来的。 上篇文章《AI不是从天而降,它经历了七十年三起三落:读懂AI的第三课》,我们知道从1950年图
( 1
min )
本文将深入浅出地讲解 JWT(JSON Web Token)在 .NET 8 中的应用。从原理到代码实战,手把手教你搭建用户登录接口颁发 Token,并配置 API 网关验证 Token,最终实现基于角色的接口权限控制,保护你的 API 不被非法访问。
( 3
min )
 一、为什么要谈 Harness Engineering 这两年,团队里关于 AI 的讨论很多,但真正落到研发现场,问题往往很具体: 为什么 AI 有时看起来很能干,有时又完全不靠谱? 为什么它能写出一段像样的代码,却经常交不出一个可验证的结果? 为什么同一个任务,换个人问、换种说法,结果差异会这么大
( 5
min )
规则链系统 https://thingsboard.io/docs/user-guide/rule-engine-2-0/re-getting-started/?scriptfunctionfilterconfig=anonymous 规则节点总共分为6大类 Filter nodes 根据不同条件过
( 14
min )
一、为什么要谈 Harness Engineering 这两年,团队里关于 AI 的讨论很多,但真正落到研发现场,问题往往很具体: 为什么 AI 有时看起来很能干,有时又完全不靠谱? 为什么它能写出一段像样的代码,却经常交不出一个可验证的结果? 为什么同一个任务,换个人问、换种说法,结果差异会这么大
( 5
min )
规则链系统 https://thingsboard.io/docs/user-guide/rule-engine-2-0/re-getting-started/?scriptfunctionfilterconfig=anonymous 规则节点总共分为6大类 Filter nodes 根据不同条件过
( 14
min )
 App Service 应用经常需要访问外部服务,比如 Azure SQL、Redis、Storage 或第三方 API。很多人会以为应用是直接从 worker 实例访问公网,但实际上并不是这样。 App Service 的 worker 实例运行在 scale unit / stamp 内部,通常
( 2
min )
App Service 应用经常需要访问外部服务,比如 Azure SQL、Redis、Storage 或第三方 API。很多人会以为应用是直接从 worker 实例访问公网,但实际上并不是这样。 App Service 的 worker 实例运行在 scale unit / stamp 内部,通常
( 2
min )
 很多开发者接入聚合型 LLM API 后,会遇到一个很现实的问题:服务商只给账单接口,不提供 Web 管理后台。Token 消耗、扣费明细、成本趋势都藏在 JSON 里,看得见数据,却看不清变化。 按照上篇文章《氛围编程实战系列:先规划清楚学习路径》这个规划路径,我们今天就来用 AI 先开发一个 L
( 2
min )
背景 如果你正在用 OpenCode,大概率听说过甚至用过 oh-my-openagent——一个为 OpenCode 提供多 Agent 编排能力的插件。它的核心思路非常好:意图门控、只读隔离、并行探索、结构化输出……属实把"让 AI 自己调度 AI"这件事玩明白了。 但问题也很头疼:太不稳定了。
( 1
min )
很多开发者接入聚合型 LLM API 后,会遇到一个很现实的问题:服务商只给账单接口,不提供 Web 管理后台。Token 消耗、扣费明细、成本趋势都藏在 JSON 里,看得见数据,却看不清变化。 按照上篇文章《氛围编程实战系列:先规划清楚学习路径》这个规划路径,我们今天就来用 AI 先开发一个 L
( 2
min )
背景 如果你正在用 OpenCode,大概率听说过甚至用过 oh-my-openagent——一个为 OpenCode 提供多 Agent 编排能力的插件。它的核心思路非常好:意图门控、只读隔离、并行探索、结构化输出……属实把"让 AI 自己调度 AI"这件事玩明白了。 但问题也很头疼:太不稳定了。
( 1
min )
 原文链接:https://mp.weixin.qq.com/s/gs-yR2R-ZTJeYx0r2ow1PA 欢迎关注公zh: AI-Frontiers RAG往期文章推荐 RAG效果差?7个指标让你的准确率大幅提升 RAG评测完整指南:指标、测试和最佳实践 收藏!RAG核心工具大全: 7大解析
( 3
min )
读《图解HTTP》:代理、网关、隧道与缓存到底是什么? 本文是阅读《图解HTTP》第 5 章后的学习整理,结合个人理解做了少量补充。文中的流程图和表格用于概括本章概念,不使用原书截图,也不替代原书内容。 这篇文章解决什么问题 我们平时访问一个网站时,直觉上会以为浏览器直接连到了目标服务器。实际情况往
( 2
min )
原文链接:https://mp.weixin.qq.com/s/gs-yR2R-ZTJeYx0r2ow1PA 欢迎关注公zh: AI-Frontiers RAG往期文章推荐 RAG效果差?7个指标让你的准确率大幅提升 RAG评测完整指南:指标、测试和最佳实践 收藏!RAG核心工具大全: 7大解析
( 3
min )
读《图解HTTP》:代理、网关、隧道与缓存到底是什么? 本文是阅读《图解HTTP》第 5 章后的学习整理,结合个人理解做了少量补充。文中的流程图和表格用于概括本章概念,不使用原书截图,也不替代原书内容。 这篇文章解决什么问题 我们平时访问一个网站时,直觉上会以为浏览器直接连到了目标服务器。实际情况往
( 2
min )
 你在用 Manim 制作一次函数图像的对比动画时,是不是也遇到过这种麻烦:想直观展示不同斜率 k 和截距 b 对直线的影响,但每改一个参数,都得重新手算两端点坐标、重新算与坐标轴的交点,甚至要凭感觉“拉长”线段保证它贯穿画面。 改三组参数,工作量就翻三倍。 今天这篇文章,就是要彻底解决这个体力活。我
( 3
min )
你在用 Manim 制作一次函数图像的对比动画时,是不是也遇到过这种麻烦:想直观展示不同斜率 k 和截距 b 对直线的影响,但每改一个参数,都得重新手算两端点坐标、重新算与坐标轴的交点,甚至要凭感觉“拉长”线段保证它贯穿画面。 改三组参数,工作量就翻三倍。 今天这篇文章,就是要彻底解决这个体力活。我
( 3
min )
 前言 最近在探索用 AI 辅助前端开发,尝试了一个有意思的实验:完全通过自然语言描述,让 AI 生成一个科幻电影风格的智慧城市 3D 数据大屏。效果出乎意料——不仅有完整的 Three.js 3D 城市场景,还有数据面板、交互控制、动画效果,而且代码质量远超预期。 先看最终效果: 济南市智慧城市大脑
( 3
min )
前言 最近在探索用 AI 辅助前端开发,尝试了一个有意思的实验:完全通过自然语言描述,让 AI 生成一个科幻电影风格的智慧城市 3D 数据大屏。效果出乎意料——不仅有完整的 Three.js 3D 城市场景,还有数据面板、交互控制、动画效果,而且代码质量远超预期。 先看最终效果: 济南市智慧城市大脑
( 3
min )
 Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653196
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653316
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3656781
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3669623
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3672641
Revive Adserver disclosed a bug submitted by v3rtical: https://hackerone.com/reports/3678828
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3680090
Revive Adserver disclosed a bug submitted by rajib_mahmud: https://hackerone.com/reports/3744200
curl disclosed a bug submitted by arkss: https://hackerone.com/reports/3773293
curl disclosed a bug submitted by hualuo: https://hackerone.com/reports/3770979
curl disclosed a bug submitted by lvtable: https://hackerone.com/reports/3767963
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653196
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653316
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3656781
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3669623
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3672641
Revive Adserver disclosed a bug submitted by v3rtical: https://hackerone.com/reports/3678828
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3680090
Revive Adserver disclosed a bug submitted by rajib_mahmud: https://hackerone.com/reports/3744200
curl disclosed a bug submitted by arkss: https://hackerone.com/reports/3773293
curl disclosed a bug submitted by hualuo: https://hackerone.com/reports/3770979
curl disclosed a bug submitted by lvtable: https://hackerone.com/reports/3767963
curl disclosed a bug submitted by tpfeng: https://hackerone.com/reports/3756699
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3751701
curl disclosed a bug submitted by tpfeng: https://hackerone.com/reports/3756699
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3751701
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653196
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653316
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3656781
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3669623
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3672641
Revive Adserver disclosed a bug submitted by v3rtical: https://hackerone.com/reports/3678828
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3680090
Revive Adserver disclosed a bug submitted by rajib_mahmud: https://hackerone.com/reports/3744200
curl disclosed a bug submitted by arkss: https://hackerone.com/reports/3773293
curl disclosed a bug submitted by hualuo: https://hackerone.com/reports/3770979
curl disclosed a bug submitted by lvtable: https://hackerone.com/reports/3767963
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653196
Revive Adserver disclosed a bug submitted by titanrain: https://hackerone.com/reports/3653316
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3656781
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3669623
Revive Adserver disclosed a bug submitted by 0x4c616e: https://hackerone.com/reports/3672641
Revive Adserver disclosed a bug submitted by v3rtical: https://hackerone.com/reports/3678828
Revive Adserver disclosed a bug submitted by 3l4: https://hackerone.com/reports/3680090
Revive Adserver disclosed a bug submitted by rajib_mahmud: https://hackerone.com/reports/3744200
curl disclosed a bug submitted by arkss: https://hackerone.com/reports/3773293
curl disclosed a bug submitted by hualuo: https://hackerone.com/reports/3770979
curl disclosed a bug submitted by lvtable: https://hackerone.com/reports/3767963
curl disclosed a bug submitted by tpfeng: https://hackerone.com/reports/3756699
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3751701
curl disclosed a bug submitted by tpfeng: https://hackerone.com/reports/3756699
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3751701
 If you extract data from iPhones for a living, Stolen Device Protection is the change you can no longer afford to ignore. It does something deceptively simple: it puts Face ID or Touch ID in front of the “Trust This Computer” prompt. The practical result is that an examiner who knows the device passcode still […]
( 12
min )
If you extract data from iPhones for a living, Stolen Device Protection is the change you can no longer afford to ignore. It does something deceptively simple: it puts Face ID or Touch ID in front of the “Trust This Computer” prompt. The practical result is that an examiner who knows the device passcode still […]
( 12
min )
 phpBB disclosed a bug submitted by misop00p: https://hackerone.com/reports/3608558
phpBB disclosed a bug submitted by misop00p: https://hackerone.com/reports/3608558
phpBB disclosed a bug submitted by misop00p: https://hackerone.com/reports/3608558
phpBB disclosed a bug submitted by misop00p: https://hackerone.com/reports/3608558
 You started looking the volumes: Then you try to remove: The solution is listing all containers, filtering by volume: Then remove the container: And finally remove the volume:
( 11
min )
You started looking the volumes: Then you try to remove: The solution is listing all containers, filtering by volume: Then remove the container: And finally remove the volume:
( 11
min )
 Brave Software disclosed a bug submitted by aaront: https://hackerone.com/reports/3693295
Brave Software disclosed a bug submitted by aaront: https://hackerone.com/reports/3693295
Brave Software disclosed a bug submitted by aaront: https://hackerone.com/reports/3693295
Brave Software disclosed a bug submitted by aaront: https://hackerone.com/reports/3693295
 Pulling a backup out of iCloud is one of the more technically demanding jobs in cloud forensics. An iCloud backup is not a single, ready-to-download file; instead, it is assembled from a large number of separate fragments that have to be collected and stitched back together into a coherent backup. Recent changes to Apple’s communication […]
( 9
min )
Pulling a backup out of iCloud is one of the more technically demanding jobs in cloud forensics. An iCloud backup is not a single, ready-to-download file; instead, it is assembled from a large number of separate fragments that have to be collected and stitched back together into a coherent backup. Recent changes to Apple’s communication […]
( 9
min )
 Rocket.Chat disclosed a bug submitted by deprrous: https://hackerone.com/reports/3734326
Rocket.Chat disclosed a bug submitted by deprrous: https://hackerone.com/reports/3734326
Rocket.Chat disclosed a bug submitted by deprrous: https://hackerone.com/reports/3734326
Rocket.Chat disclosed a bug submitted by deprrous: https://hackerone.com/reports/3734326
 Node.js disclosed a bug submitted by junius: https://hackerone.com/reports/3736889
Node.js disclosed a bug submitted by v1ct0rv0nd00m: https://hackerone.com/reports/3752489
Node.js disclosed a bug submitted by junius: https://hackerone.com/reports/3736889
Node.js disclosed a bug submitted by v1ct0rv0nd00m: https://hackerone.com/reports/3752489
Node.js disclosed a bug submitted by junius: https://hackerone.com/reports/3736889
Node.js disclosed a bug submitted by v1ct0rv0nd00m: https://hackerone.com/reports/3752489
Node.js disclosed a bug submitted by junius: https://hackerone.com/reports/3736889
Node.js disclosed a bug submitted by v1ct0rv0nd00m: https://hackerone.com/reports/3752489
 This video tutorial is very good to show how to interact with an analog pressure sensor:
( 11
min )
This video tutorial is very good to show how to interact with an analog pressure sensor:
( 11
min )
 A few days ago we wrote about YellowKey, the newest entry in what has become a remarkably long list of BitLocker bypasses. That article walked through one specific attack with a practical workflow. This follow-up steps back and surveys the broader landscape: where BitLocker has been broken before, where it is still broken today, and […]
( 23
min )
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3733946
A few days ago we wrote about YellowKey, the newest entry in what has become a remarkably long list of BitLocker bypasses. That article walked through one specific attack with a practical workflow. This follow-up steps back and surveys the broader landscape: where BitLocker has been broken before, where it is still broken today, and […]
( 23
min )
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3733946
 CoinMate.io disclosed a bug submitted by glferreira-devsecops: https://hackerone.com/reports/3676308
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3733946
CoinMate.io disclosed a bug submitted by glferreira-devsecops: https://hackerone.com/reports/3676308
curl disclosed a bug submitted by hexproof: https://hackerone.com/reports/3739561
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3735276
curl disclosed a bug submitted by hexproof: https://hackerone.com/reports/3739561
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3735276
CoinMate.io disclosed a bug submitted by glferreira-devsecops: https://hackerone.com/reports/3676308
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3733946
CoinMate.io disclosed a bug submitted by glferreira-devsecops: https://hackerone.com/reports/3676308
curl disclosed a bug submitted by hexproof: https://hackerone.com/reports/3739561
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3735276
curl disclosed a bug submitted by hexproof: https://hackerone.com/reports/3739561
curl disclosed a bug submitted by giant_anteater: https://hackerone.com/reports/3735276
 On May 12, 2026, a researcher operating under the handles Chaotic Eclipse and Nightmare-Eclipse dropped a working proof-of-concept on GitHub for a Windows zero-day called YellowKey. In short, it lets anyone with brief physical access to a BitLocker-protected Windows 11, Windows Server 2022, or Windows Server 2025 machine pop a command prompt with full read […]
( 17
min )
On May 12, 2026, a researcher operating under the handles Chaotic Eclipse and Nightmare-Eclipse dropped a working proof-of-concept on GitHub for a Windows zero-day called YellowKey. In short, it lets anyone with brief physical access to a BitLocker-protected Windows 11, Windows Server 2022, or Windows Server 2025 machine pop a command prompt with full read […]
( 17
min )
 Picking a VAPT vendor in India is harder than it should be. Every empanelled firm offers the same checklist of services on their homepage. Most reports follow the same template. And once you sign, the gap between a real attacker-mindset assessment and a glorified vulnerability scan only shows up after the work is done. This list isn’t ranked by company size, […]
The post Top 10 CERT-In Empanelled VAPT Companies in India (2026) appeared first on Payatu.
( 68
min )
Picking a VAPT vendor in India is harder than it should be. Every empanelled firm offers the same checklist of services on their homepage. Most reports follow the same template. And once you sign, the gap between a real attacker-mindset assessment and a glorified vulnerability scan only shows up after the work is done. This list isn’t ranked by company size, […]
The post Top 10 CERT-In Empanelled VAPT Companies in India (2026) appeared first on Payatu.
( 68
min )
 Over the years, we have published several articles about the extraction agent. However, the underlying technology changes quickly, and incremental changes often have significant cumulative effects. As a result, many of our older posts are no longer relevant and can be misleading if followed to the letter today. While last year’s recap, Installing and Troubleshooting […]
( 13
min )
Over the years, we have published several articles about the extraction agent. However, the underlying technology changes quickly, and incremental changes often have significant cumulative effects. As a result, many of our older posts are no longer relevant and can be misleading if followed to the letter today. While last year’s recap, Installing and Troubleshooting […]
( 13
min )
 Modern software development doesn’t really start from a blank file anymore. Instead, most of the time, it’s about putting things together. We build by connecting pieces that already exist. For example, if we need a backend quickly, something like FastAPI gets us there in minutes. If we need a quick parsing script, an LLM generates […]
The post The Chrome Extension That Stole the CEO’s Cookies: A Confession on AI, Trust, and Supply Chain Security appeared first on Payatu.
( 70
min )
Modern software development doesn’t really start from a blank file anymore. Instead, most of the time, it’s about putting things together. We build by connecting pieces that already exist. For example, if we need a backend quickly, something like FastAPI gets us there in minutes. If we need a quick parsing script, an LLM generates […]
The post The Chrome Extension That Stole the CEO’s Cookies: A Confession on AI, Trust, and Supply Chain Security appeared first on Payatu.
( 70
min )
 Turning on DNSSEC makes your domain more secure — but if it’s misconfigured, newer certificate validation rules can stop SSL renewals in their tracks.
Hey there,
You know that satisfying click when you finally turn on DNSSEC? It feels like adding a shiny new deadbolt to your domain’s front door. You’re doing the responsible thing: locking down your DNS against spoofing and hijacks, and making the internet just a bit safer.
Continue reading DNSSEC: The Extra Security Layer That Can Break Your Padlock at Sucuri Blog.
( 7
min )
Turning on DNSSEC makes your domain more secure — but if it’s misconfigured, newer certificate validation rules can stop SSL renewals in their tracks.
Hey there,
You know that satisfying click when you finally turn on DNSSEC? It feels like adding a shiny new deadbolt to your domain’s front door. You’re doing the responsible thing: locking down your DNS against spoofing and hijacks, and making the internet just a bit safer.
Continue reading DNSSEC: The Extra Security Layer That Can Break Your Padlock at Sucuri Blog.
( 7
min )
 Extracting cloud data becomes increasingly valuable – and increasingly complex at the same time. In scenarios where a target device is physically unavailable cloud extraction is often the only real way to access evidence. This is particularly relevant when devices are secured by an unknown passcode or locked under Apple’s Stolen Device Protection framework without […]
( 6
min )
curl disclosed a bug submitted by sdainard: https://hackerone.com/reports/3666576
curl disclosed a bug submitted by bonaire: https://hackerone.com/reports/3621851
curl disclosed a bug submitted by sdainard: https://hackerone.com/reports/3666576
curl disclosed a bug submitted by bonaire: https://hackerone.com/reports/3621851
Extracting cloud data becomes increasingly valuable – and increasingly complex at the same time. In scenarios where a target device is physically unavailable cloud extraction is often the only real way to access evidence. This is particularly relevant when devices are secured by an unknown passcode or locked under Apple’s Stolen Device Protection framework without […]
( 6
min )
curl disclosed a bug submitted by sdainard: https://hackerone.com/reports/3666576
curl disclosed a bug submitted by bonaire: https://hackerone.com/reports/3621851
curl disclosed a bug submitted by sdainard: https://hackerone.com/reports/3666576
curl disclosed a bug submitted by bonaire: https://hackerone.com/reports/3621851
 We updated iOS Forensic Toolkit, adding low-level extraction support for iOS 26 and 26.0.1 via the extraction agent. This support is available for most iPhones and iPads compatible with the iOS 26 branch with a notable exception of the iPhone 17 range and M5-based iPads. Why exactly are these devices exempt, and what else did […]
( 11
min )
We updated iOS Forensic Toolkit, adding low-level extraction support for iOS 26 and 26.0.1 via the extraction agent. This support is available for most iPhones and iPads compatible with the iOS 26 branch with a notable exception of the iPhone 17 range and M5-based iPads. Why exactly are these devices exempt, and what else did […]
( 11
min )
 This project is really cool and it is in my TODO list! https://github.com/0x23/MicroManipulatorStepper
( 11
min )
This project is really cool and it is in my TODO list! https://github.com/0x23/MicroManipulatorStepper
( 11
min )
 MIME type confusion, content sniffing abuse, and a sneaky bypass of a previous Firefox patch This bug is a bypass. It doesn’t introduce any new primitive on its own; it sidesteps a fix Mozilla shipped for CVE-2025-1936 without realising the sanitization was only half-done. To understand why it works, you need to dig into how […]
The post How a Double-Encoded Null Byte Turns a ZIP File into an XSS Vector – CVE-2026-2790 appeared first on Payatu.
( 67
min )
MIME type confusion, content sniffing abuse, and a sneaky bypass of a previous Firefox patch This bug is a bypass. It doesn’t introduce any new primitive on its own; it sidesteps a fix Mozilla shipped for CVE-2025-1936 without realising the sanitization was only half-done. To understand why it works, you need to dig into how […]
The post How a Double-Encoded Null Byte Turns a ZIP File into an XSS Vector – CVE-2026-2790 appeared first on Payatu.
( 67
min )
 In traditional forensic workflows, gaining access to a Windows system was a straightforward exercise: extract the NT hashes from a local database and run a fast (very fast!) offline attack. Today, Windows authentication is moving away from those essentially insecure NTLM hashes toward more resilient mechanisms. Microsoft is actively steering users away from local Windows […]
( 8
min )
In traditional forensic workflows, gaining access to a Windows system was a straightforward exercise: extract the NT hashes from a local database and run a fast (very fast!) offline attack. Today, Windows authentication is moving away from those essentially insecure NTLM hashes toward more resilient mechanisms. Microsoft is actively steering users away from local Windows […]
( 8
min )
 Overview
During a recent malware cleanup investigation, we encountered a compromised Joomla website where the site owner reported a strange issue. Their website displayed a large number of suspicious product links that had nothing to do with their business. These products were not added by the website owner and did not exist in their catalog.
Visitors and search engines were seeing pages that promoted unrelated products, raising immediate concerns about spam injection or remote content manipulation.
Continue reading Joomla SEO Spam Injector: Obfuscated PHP Backdoor Hijacking Site Visitors at Sucuri Blog.
( 8
min )
Overview
During a recent malware cleanup investigation, we encountered a compromised Joomla website where the site owner reported a strange issue. Their website displayed a large number of suspicious product links that had nothing to do with their business. These products were not added by the website owner and did not exist in their catalog.
Visitors and search engines were seeing pages that promoted unrelated products, raising immediate concerns about spam injection or remote content manipulation.
Continue reading Joomla SEO Spam Injector: Obfuscated PHP Backdoor Hijacking Site Visitors at Sucuri Blog.
( 8
min )
 In our last 20 IoT security assessments across automotive, MedTech, and consumer electronics, 17 devices had at least one debug interface (UART or JTAG) left fully accessible in production. In 9 of those cases, the exposed interface gave us an unauthenticated root shell within minutes of opening the enclosure. That single finding class alone invalidated every software-level security […]
The post IoT Penetration Testing: A Complete Methodology Guide with the OWASP ISTG Framework appeared first on Payatu.
( 72
min )
In our last 20 IoT security assessments across automotive, MedTech, and consumer electronics, 17 devices had at least one debug interface (UART or JTAG) left fully accessible in production. In 9 of those cases, the exposed interface gave us an unauthenticated root shell within minutes of opening the enclosure. That single finding class alone invalidated every software-level security […]
The post IoT Penetration Testing: A Complete Methodology Guide with the OWASP ISTG Framework appeared first on Payatu.
( 72
min )
 Web applications today rely heavily on caching to improve performance and reduce server load. CDNs like Cloudflare, Akamai, and reverse proxies like Nginx store frequently requested content so users get faster responses. But when these caching systems are misconfigured or behave unexpectedly, they can become serious security vulnerabilities. This post covers two related but different […]
The post Web Cache Poisoning vs Deception: The Dynamic Duo of Cache Attacks appeared first on Payatu.
( 73
min )
Web applications today rely heavily on caching to improve performance and reduce server load. CDNs like Cloudflare, Akamai, and reverse proxies like Nginx store frequently requested content so users get faster responses. But when these caching systems are misconfigured or behave unexpectedly, they can become serious security vulnerabilities. This post covers two related but different […]
The post Web Cache Poisoning vs Deception: The Dynamic Duo of Cache Attacks appeared first on Payatu.
( 73
min )
 India finally has its data protection law. Europe has had one since 2018. If your organisation sits at the intersection of both, you are now subject to two comprehensive privacy regimes simultaneously, and the gaps between them are where the risk lives. A New Privacy Reality for Indian Businesses For years, Indian technology companies, IT […]
The post GDPR Meets DPDP: What Every Indian CISO Operating in the EU Must Know appeared first on Payatu.
( 70
min )
Just use these two commands:
( 11
min )
These are some implementations I found in the Internet: Javascript: https://github.com/ibid-11962/Windows-95-3D-Maze-Screensaver Rust: https://github.com/clrnd/win95-maze-rs (This is not a recreation) This guy added navigation control to the original 3D Maze screenshot: https://github.com/x86matthew/Playable3DMaze
( 11
min )
These are the steps I use: Initialize the BOOTP/DHCPD service: In the maxbox run the default u-boot command to flash the device: That is it!
( 11
min )
India finally has its data protection law. Europe has had one since 2018. If your organisation sits at the intersection of both, you are now subject to two comprehensive privacy regimes simultaneously, and the gaps between them are where the risk lives. A New Privacy Reality for Indian Businesses For years, Indian technology companies, IT […]
The post GDPR Meets DPDP: What Every Indian CISO Operating in the EU Must Know appeared first on Payatu.
( 70
min )
Just use these two commands:
( 11
min )
These are some implementations I found in the Internet: Javascript: https://github.com/ibid-11962/Windows-95-3D-Maze-Screensaver Rust: https://github.com/clrnd/win95-maze-rs (This is not a recreation) This guy added navigation control to the original 3D Maze screenshot: https://github.com/x86matthew/Playable3DMaze
( 11
min )
These are the steps I use: Initialize the BOOTP/DHCPD service: In the maxbox run the default u-boot command to flash the device: That is it!
( 11
min )
 <link rel="stylesheet" type="text/css" hr
( 5
min )
<link rel="stylesheet" type="text/css" hr
( 5
min )
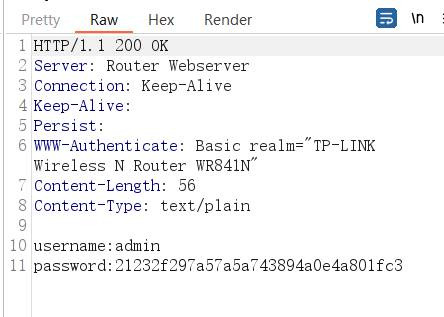 <link rel="stylesheet" type="text/css" hr
( 3
min )
<link rel="stylesheet" type="text/css" hr
( 3
min )
 既然这是Project Zero的BigSleep发现的第一个V8漏洞,Buff这么多,那就很难不来一窥究竟了。
( 3
min )
既然这是Project Zero的BigSleep发现的第一个V8漏洞,Buff这么多,那就很难不来一窥究竟了。
( 3
min )
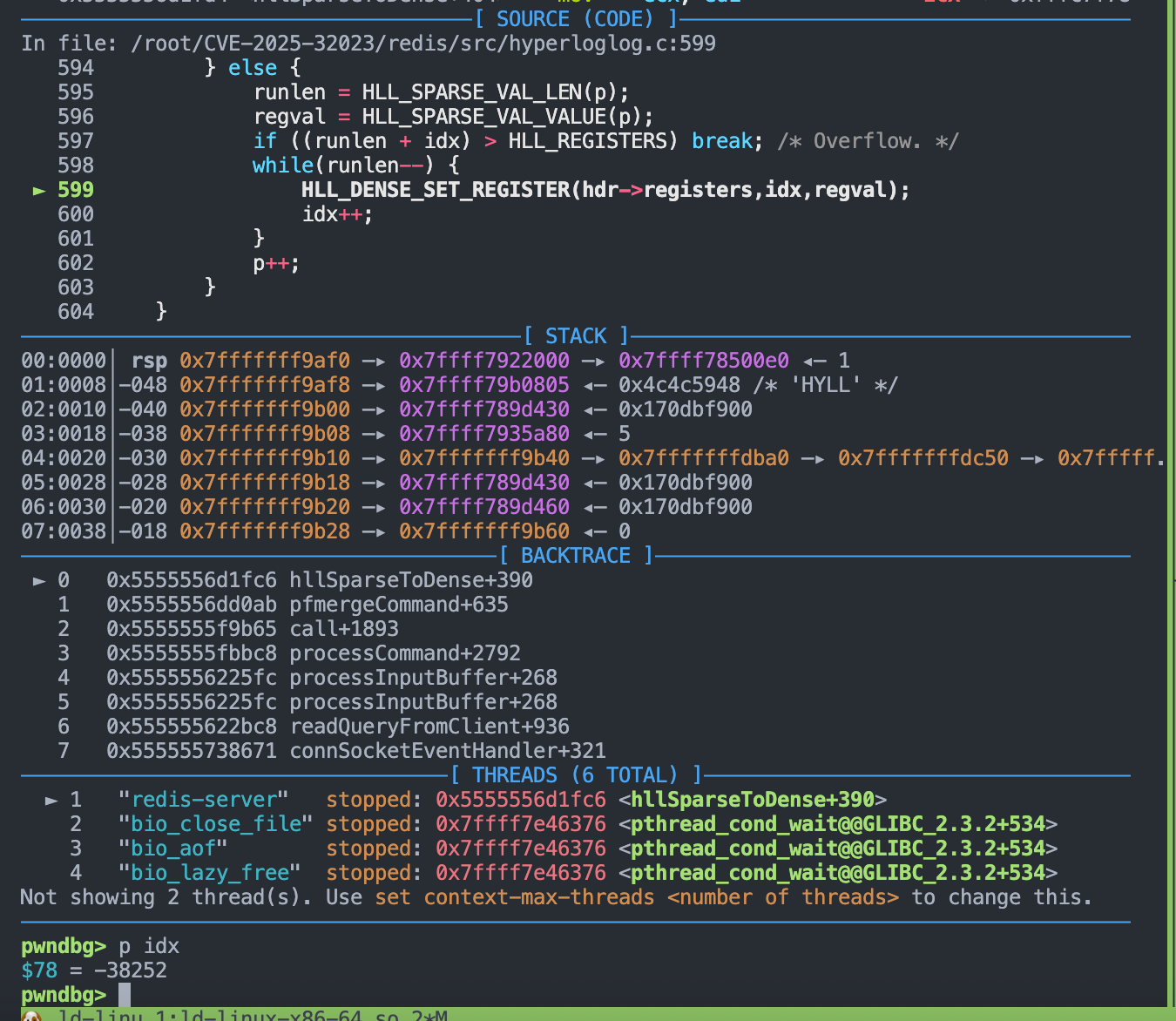 <link rel="stylesheet" type="text/css" hr
( 6
min )
<link rel="stylesheet" type="text/css" hr
( 6
min )
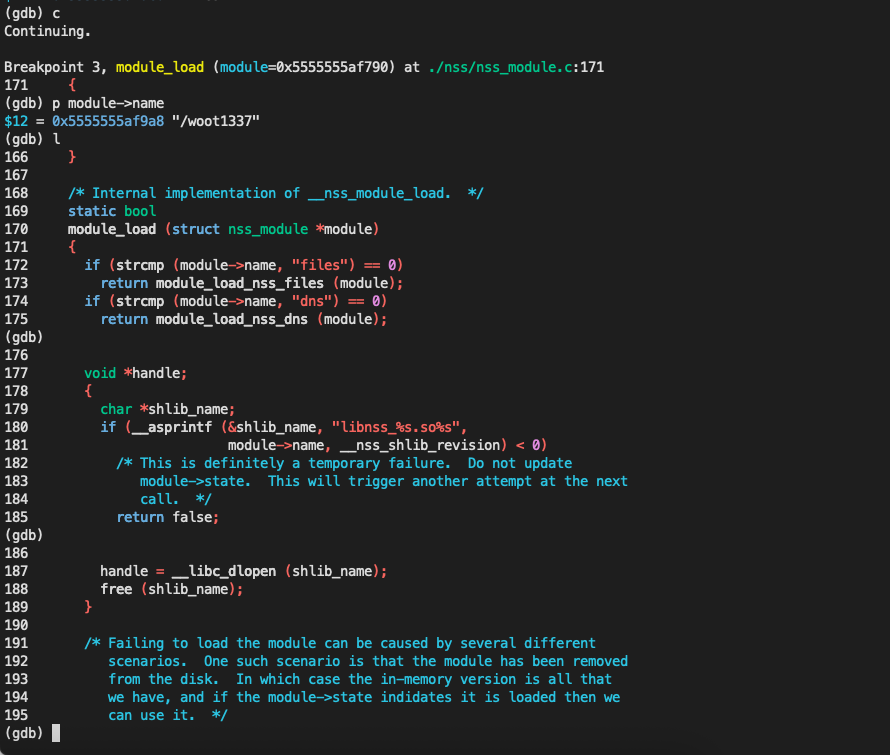 <link rel="stylesheet" type="text/css" hr
( 9
min )
<link rel="stylesheet" type="text/css" hr
( 9
min )